تأثیر هوش مصنوعی بر تحول پژوهشهای علمی انکار ناپذیر است



آخرین الگوریتمهای هوش مصنوعی به بررسی تکامل کهکشانها، محاسبهی توابع موج کوانتومی، کشف ترکیبهای شیمیایی جدید و بسیاری از موارد دیگر میپردازند. آیا کاری وجود دارد که نتوان به خودکارسازی آن پرداخت؟
هیچ انسان یا گروهی از انسانها نمیتوانند پابهپای انبوه اطلاعات تولیدشده در آزمایشهای کنونی فیزیک و ستارهشناسی به پژوهش بپردازد. گاهی حجم روزانهی اطلاعات به چندین ترابایت میرسد؛ بشر با سیلابی از اطلاعات روبهرو است که بهصورت پیوسته ادامه دارد و رشد میکند. برای مثال تلسکوپ رادیویی SKA (آرایهی کیلومترمربعی) قرار است در اواسط دههی ۲۰۲۰ فعالیت خود را آغاز کند. حجم دادههای سالانهای که این تلسکوپ تولید میکند میتواند به اندازهی حجم کل ترافیکی سالانهی اینترنت باشد.
این طوفان اطلاعاتی باعث شده است بسیاری از دانشمندان برای پژوهش از هوش مصنوعی کمک بگیرند. سیستمهای AI ازجمله شبکههای عصبی مصنوعی (شبکههای کامپیوتری که براساس نورونها شبیهسازی شدهاند و به تقلید از عملکرد مغز میپردازند) میتوانند به کوهی از دادهها نفوذ کنند، ناهنجاریها را مشخص کنند و الگوهایی غیرقابل تشخیص برای انسان را شناسایی کنند.

البته، قدمت استفاده از کامپیوتر برای پژوهشهای علمی به ۷۵ سال پیش و روش دستی بررسی دادهها برای جستجوی الگوهای بامفهوم به هزاران سال پیش بازمیگردد؛ امروز هم به اعتقاد بعضی دانشمندان، ازطریق جدیدترین فناوریهای یادگیری ماشین و هوش مصنوعی میتوان به روش جدیدی برای پژوهش علمی رسید.
روش جدید که مدلسازی مولد نام گرفته است، میتواند بدون هیچگونه دانش برنامهریزیشده از فرآیندهای فیزیکی و صرفا براساس دادهها، قابلقبولترین نظریه را از میان توضیحات رقیب پیدا کند. طرفداران مدل مولد، این مدل را روش سوم یادگیری معرفی کردهاند.
انسان از دیرباز ازطریق مشاهده به یادگیری و کسب اطلاعات در مورد جهان پرداخته است. برای مثال یوهانس کپلر ستارهشناس با بررسی جدولهای تیکو براهه در مورد موقعیت سیارهها سعی میکرد الگوهای اصلی آنها را تشخیص دهد. او درنهایت به این نتیجه رسید که سیارهها در مدارهای بیضیشکل حرکت میکنند.
علم هم ازطریق شبیهسازی پیشرفت کرده است. ستارهشناسان میتوانند با مدلسازی حرکت کهکشان راهشیری و کهکشان همسایهی آن، آندرومدا، برخورد این دو کهکشان در چند میلیون سال آینده را پیشبینی کنند. دانشمندان با شبیهسازی و مشاهدهی پدیدهها میتوانند فرضیه تولید کنند و سپس با مشاهدات بعدی به تست همان فرضیهها بپردازند؛ اما مدلسازی مولد متفاوت است. بهگفتهی کوین شاوینسکی، اخترفیزیکدان و یکی از طرفداران مدلسازی مولد که اخیرا در مؤسسهی فدرال فناوری زوریخ مشغول به کار شده است:
مدلسازی مولد روش سوم یادگیری است که بین مشاهده و شبیهسازی قرار میگیرد و به مسئله حمله میکند
برخی دانشمندان مدلسازی مولد و روشهای جدید دیگر را بهمثابه ابزار قدرتمندی برای پژوهش سنتی در نظر میگیرند؛ اغلب آنها بر سر تأثیرهای غیرقابلانکار هوش مصنوعی بر علم و نقش روزافزون آن توافق دارند. برایان نورد، اخترفیزیکدان آزمایشگاه ملی شتابدهندهی فِرمی است که از شبکههای مصنوعی عصبی برای بررسی کیهان استفاده میکند. او یکی از افرادی است که از خودکارسازی وظایف دانشمندان هراس دارد.
اکتشاف براساس تولید
شاوینسکی از زمان فارغالتحصیلی از دبیرستان، درزمینهی علم دادهمحور کار کرده است. او در طول دورهی دکترا، کارهای خستهکنندهای مثل طبقهبندی هزاران کهکشان براساس ظاهر را انجام داده است. آن زمان هیچ نرمافزاری برای این کار وجود نداشت بنابراین شاوینسکی تصمیم به برونسپاری این کار گرفت و بهاینترتیب پروژهی علمی شهروند Galaxy Zoo شکل گرفت.
از سال ۲۰۰۷، کاربران عادی کامپیوتر با وارد کردن بهترین حدسیات خود در مورد دستهبندی کهکشانها به ستارهشناسان در این وظیفه کمک کردند و نقش عمدهای در تصحیح طبقهبندیها ایفا کردند. این پروژه یک موفقیت بزرگ بود اما به عقیدهی شاوینسکی، هوش مصنوعی این کار را منسوخ کرده است او میگوید:
امروزه، دانشمند بااستعداد و باسابقه درزمینهی یادگیری ماشین، با دسترسی به رایانش ابری میتوانند در یک بعدازظهر این وظیفه را بهراحتی انجام دهند
شاوینسکی در سال ۲۰۱۶ به ابزار جدید و قدرتمند مدلسازی مولد روی آورد. در مدلسازی مولد، با توجه بهشرط X خروجی Y به دست میآید. این روش بسیار فراگیر و قدرتمند است. بهعنوانمثال، فرض کنید یک مجموعه از تصاویر چهرهی انسان را بهعنوان ورودی به مدل مولد بدهید.
در این مثال، هر چهره دارای یک برچسب سنی است. برنامهی کامپیوتری با دقت بالایی «دادههای آموزشی» را برسی میکند و بین چهرههای مسنتر و احتمال افزایش چروک ارتباط برقرار میکند. درنهایت میتواند سن چهرههای ورودی را تشخیص دهد. بر همین اساس میتواند تغییرات فیزیکی احتمالی چهرهها با افزایش سن را تخمین بزند.
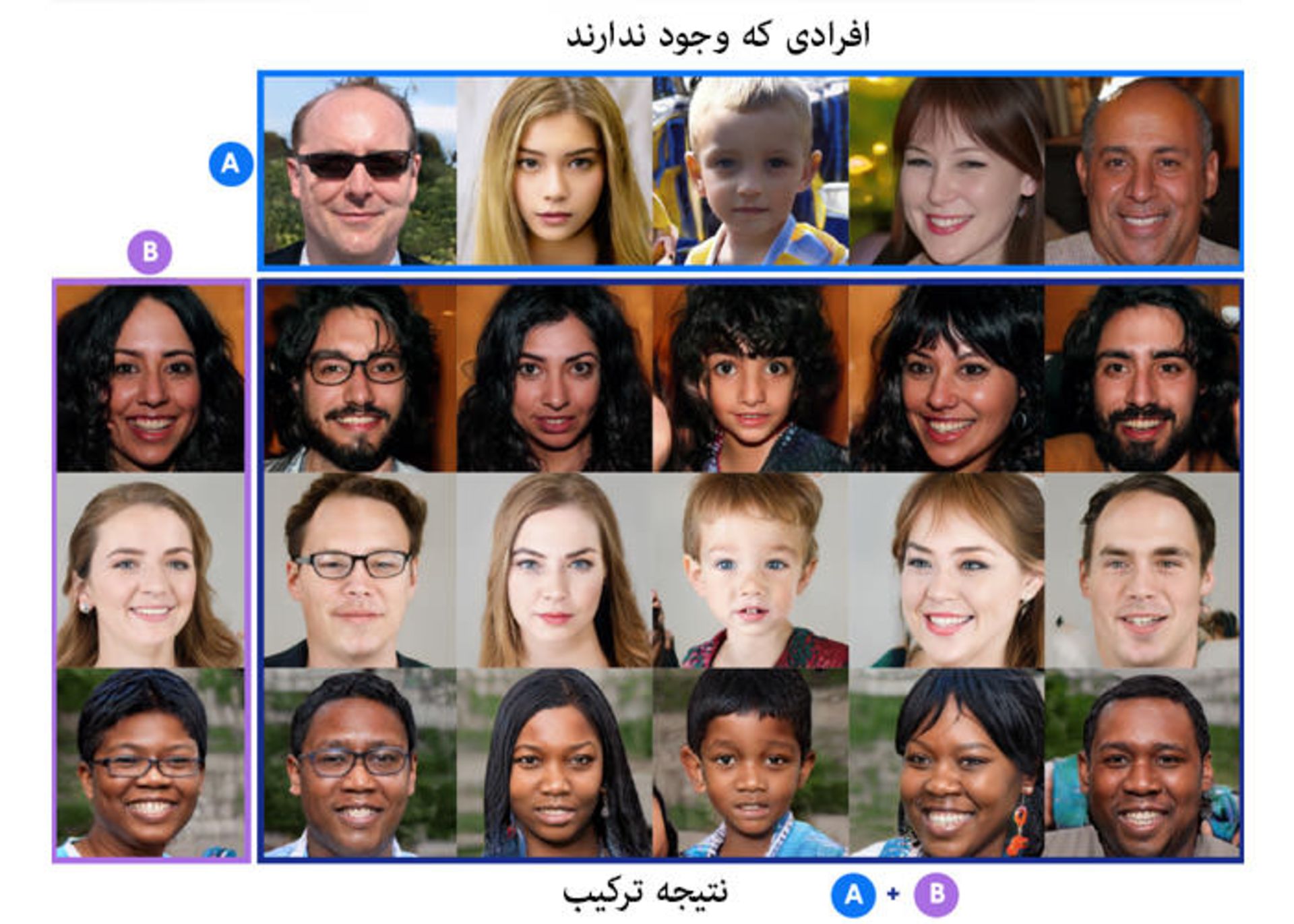
هیچکدام از این چهرهها واقعی نیستند. چهرههای سطر بالا (A) و ستون سمت چپ (B) با استفاده از عناصر سازندهی چهرههای واقعی، توسط شبکهی مولد تخاصمی (GAN) تولید شدهاند. در مرحلهی بعدی، GAN مشخصات اصلی چهرههای سطر A ازجمله جنسیت، سن و شکل چهره را با مشخصات جزئیتر چهرههای B ازجمله رنگ مو و رنگ چشم ترکیب کرد تا سایر چهرههای داخل شبکه تولید شوند.
شناختهشدهترین سیستمهای مدلسازی مولد، «شبکههای مولد تخاصمی» (GAN) هستند. GAN پس از یادگیری دادهها میتواند تصاویر خراب یا پیکسلهای مفقود را ترمیم کند یا میتواند وضوح تصاویر تار را بالا ببرد. این شبکهها ازطریق رقابت میتوانند به شناسایی اطلاعات مفقود بپردازند (به همین دلیل «تخاصمی» لقب گرفتهاند).
بخشی از شبکه موسوم به مولد، به تولید دادههای جعلی میپردازد درحالیکه بخش دیگر یعنی تفکیککننده، سعی میکند دادههای جعلی را از دادههای واقعی تشخیص دهد. هر دو بخش این برنامه بهمرور بهبودیافتهاند. برای مثال اخیرا GAN موفق به تولید چهرههایی بسیار واقعی شده است؛ تصاویری واقعی از افرادی که وجود خارجی ندارند.
علاوه بر این، مدلسازی مولد مجموعهای از دادهها را دریافت میکند (معمولا تصاویر) و هرکدام از آنها را به یک مجموعه از بلوکهای سازندهی انتزاعی و ابتدایی تجزیه میکند. دانشمندان به این بلوکها «فضای پنهان» میگویند. فضای پنهان، فضایی است که دادههای آن در یک لایهی تنگنا قرار میگیرند.
شبکه الگوی تخاصمی ازطریق رقابت دادههای مفقود را شناسایی میکند
بهبیاندیگر بخشی از دادهها در فضای قابلمشاهده قرار دارند و سپس به فضایی پنهان نگاشته میشوند که در این فضا نقاط دادهای به یکدیگر نزدیک هستند. الگوریتم، عناصر فضای پنهان را برای بررسی تأثیر آنها بر دادههای اصلی تغییر میدهد و به این صورت به افشای فرآیندهای فیزیکی سیستم کمک میکند.
فضای پنهان انتزاعی است و بصریسازی آن کار دشواری است. برای مثال عملکرد مغز هنگام تعیین جنسیت براساس چهرهی انسان را در نظر بگیرید. شاید مدل مو، شکل بینی و موارد دیگر و حتی الگوهایی را تشخیص دهید که نتوانید بهراحتی آنها را به زبان بیاورید. برنامهی کامپیوتری هم با روش مشابهی در میان دادهها به جستجوی ویژگیهای برجسته میپردازد: اگرچه نمیداند سبیل چیست یا جنسیت چیست، اما اگر براساس مجموعه دادههایی با برچسب «زن» یا «مرد» آموزش ببیند که برخی از آنها برچسب «سبیل» دارند، میتواند بهسرعت ارتباط لازم را پیدا کند.
شاوینسکی، دنیس تورپ و شی ژانگ، همکاران او در مؤسسهی فناوری فدرال زوریخ (ETH)، در دسامبر سال گذشته مقالهای را در مجلهی اخترشناسی و اخترفیزیک منتشر کردند که در آن از مدلسازی مولد برای بررسی تغییرات فیزیکی کهکشانها در طول تکامل استفاده کردند (نرمافزار مورداستفادهی آنها به شیوهای متفاوت با شبکهی مولد تخاصمی، با فضای پنهان رفتار میکند؛ بنابراین وجود شباهتها، از الگوی GAN استفاده نمیکند).
مدل آنها بهعنوان روشی برای تست فرضیههای فیزیکی، مجموعه دادههای مصنوعی تولید کرد. برای مثال آنها اطلاعاتی را در مورد رابطهی خاموش شدن شکلگیری ستارهها (کاهش شدید نرخ شکلگیری) با افزایش چگالی کهکشان جستوجو کردند.

کوین شاوینسکی، اخترفیزیکدان و بنیانگذار شرکت هوش مصنوعی Modulos معتقد است، روشی به نام مدلسازی مولد، روش سوم یادگیری دربارهی جهان است.
سؤال اصلی شاوینسکی این است که صرفا از دادهها تا چه اندازه میتوان به اطلاعاتی در مورد فرآیندهای ستارهای و کهکشانی رسید. او میگوید:
بیایید هر آنچه در مورد اخترفیزیک میدانیم را پاک کنیم و ببینم تا چه اندازه میتوانیم تمام آن دانش را تنها با استفاده از دادهها مجددا به دست آوریم؟
در مرحلهی اول تصاویر کهکشان به فضای پنهان تقلیل پیدا کردند، سپس شاوینسکی یکی از عناصر آن فضا را بهگونهای تنظیم کرد که متناظر با تغییر مشخصی در محیط کهکشانی باشد (برای مثال چگالی محیط اطراف). در مرحلهی بعد میتوان با بازسازی کهکشان به تفاوتها پی برد. شاوینسکی در این مورد توضیح میدهد:
براساس فرضیهی ماشین مولد، میتوانیم کل کهکشانهای محیط کمچگالی را بهگونهای تبدیل کنیم که گویی در یک محیط با چگالی بالا قرار دارند.
در این آزمایش، پس از ورود کهکشانها از محیطهای کمچگالی به محیطهای چگال، رنگ آنها روی به سرخی رفت و شدت نور مرکز ستارهها افزایش یافت. بهگفتهی شاوینسکی این نتیجه دقیقا منطبق با مشاهدات واقعی کهکشانها است اما علت آن چیست.
مرحلهی بعدی هنوز خودکارسازی نشده است؛ درنتیجه شاوینسکی در این مرحله باید بهعنوان کاربری انسانی این سؤال را مطرح کند که چه نوع فیزیکی منجر به این پدیده میشود؟ برای این فرایند، دو توضیح احتمالی وجود دارد: شاید علت سرخی کهکشانها در محیط چگال، وجود گاز و غبار بیشتر باشد.
دلیل دیگر سرخی ستارهها این است که در مرحلهی مرگ قرار دارند (بهبیاندیگر، سن ستارهها بالاتر است). با مدل مولد، میتوان هر دو ایده را آزمایش کرد. به همین دلیل عناصر فضای پنهان برای بررسی تأثیر هر دو مورد تغییر داده شدند. بهگفتهی شاوینسکی:
پاسخ واضح است. کهکشانهای سرختر مسنتر هستند و تغییرات غبار تأثیری بر سرخی ندارند؛ بنابراین تعریف اول صحیح است.

اخترفیزیکدانها با مدلسازی مولد میتوانند به تغییرات کهکشانها پس از ورود به محیطهای چگال (از محیطهای کمچگالی) و فرآیندهای فیزیکی مربوطبه این تغییرات پی ببرند.
این روش به شبیهسازی سنتی مربوط است اما تفاوت زیادی با آن دارد. بهگفتهی شاوینسکی:
شبیهسازی مبتنی بر فرضیه است؛ اما در این روش از قوانین فیزیکی سیستم آگاه هستیم؛ بنابراین دستورالعمل شکلگیری ستارهها، دستورالعمل رفتار مادهی تاریک و بسیاری از موارد دیگر را داریم. حالا تمام این فرضیهها را وارد کرده و سپس شبیهسازی را اجرا میکنیم. پس از اجرا میپرسیم: آیا این نتیجه به واقعیت شباهتی دارد؟ به این روش مدلسازی مولد میگویند که از یک نظر، دقیقا نقطهی مقابل شبیهسازی است. در این روش ما چیزی نمیدانیم؛ نمیخواهیم هیچ فرضی داشته باشیم. فقط از دادهها میخواهیم واقعیت را بگویند.
موفقیت آشکار مدلسازی مولد در چنین بررسیهایی بهمعنی بیهوده بودن تلاش ستارهشناسان یا فارغالتحصیلان ستارهشناسی نیست. بلکه ثابت میکند که میتوان ازطریق سیستمهای هوش مصنوعی به یادگیری در مورد اجرام و فرآیندهای نجومی پرداخت. سیستمی که علاوه بر دسترسی به انبوه دادهها به ابزارهای دیگری هم مجهز است. شاوینسکی میگوید:
این روش بهمعنی علم تمام خودکار نیست. بلکه قابلیت ساخت ابزار برای خودکارسازی فرآیندهای علمی را ثابت میکند.
مدلسازی مولد ابزار قدرتمندی است، اما هنوز بر سر نامگذاری آن بهعنوان روش جدید یادگیری علمی بحث وجود دارد. دیوید هاگ، کیهانشناس دانشگاه نیویورک و مؤسسهی فلاتیرون (که مانند کوانتا با سرمایهگذاری مؤسسهی سیمونز تأسیس شده است)، این روش تأثیرگذار را تنها بهعنوان روشی پیچیده برای استخراج الگوهای دادهای پذیرفته است؛ کاری که ستارهشناسان قرنها بهصورت دستی انجام دادهاند.
بهبیاندیگر، این روش شکل پیچیدهای از مشاهده همراهبا تحلیل است. کار هاگ هم مانند شاوینسکی بهشدت به هوش مصنوعی وابسته است؛ او از شبکههای عصبی، برای دستهبندی ستارهها براساس طیف و استخراج ویژگیهای فیزیکی آنها استفاده میکند؛ اما کار خود و شاوینسکی را علم آزمونوخطا میداند او میگوید:
فکر نمیکنم، این مدلسازی روش سوم یادگیری باشد. بلکه معتقدم با این روش، صرفا رویکرد جامعه نسبت به کاربرد دادهها پیچیدهتر میشود. از طرفی هدف ما بهبود مقایسهی دادهها با یکدیگر است؛ اما به نظر من، این قبیل پروژهها هنوز از نوع یادگیری عینی هستند.
دستیاران سختکوش
صرفنظر از نوآوری شبکههای عصبی و هوش مصنوعی، نقش ضروری آنها در پژوهشهای معاصر فیزیک و ستارهشناسی بر کسی پوشیده نیست. کای پولسترر از مؤسسهی مطالعات نظری هیدلبرگ، سرپرستی گروه انفورماتیک نجوم را بر عهده دارد. هدف این گروه تمرکز بر روشهای جدید دادهمحور علم اخترفیزیک است. این گروه اخیرا برای استخراج اطلاعات انتقال سرخ از مجموعه دادههای کهکشان، از نوعی الگوریتم یادگیری ماشین استفاده کرده است.
پولسترر سیستمهای جدید مبتنی بر AI را دستیاران سختکوشی میداند که میتوانند با دقت بالا در زمان نامحدود بدون خستگی یا شکایت از شرایط کار به تحلیل دادهها بپردازند. این سیستمها میتوانند کارهای خستهکننده را انجام دهند و بخش جذاب علم را بر عهدهی دانشمندان بگذارند.
اما این سیستمها هم خالی از عیب نیستند. بهویژه پلسترر هشدار میدهد، الگوریتمها تنها قادر به انجام کارهایی هستند که براساس آن آموزش دیده باشند. سیستم نسبت به ورودی خود «ندانمگرا» است. اگر یک کهکشان را بهعنوان ورودی به آن بدهید، میتواند انتقال سرخ و سن آن را تخمین بزند. اما برای مثال یک تصویر سلفی یا تصویر یک ماهی فاسد را به آن بدهید، باز هم سن را بهعنوان خروجی برمیگرداند. درنهایت، نظارت دانشمند انسانی ضروری است و پلسترر بر نقش پژوهشگر بهعنوان مسئول تفسیر دادهها تأکید میکند.
سیستم هوش مصنوعی نسبت به ورودی خود ندانم گرا است
به عقیدهی نورد، شبکههای عصبی تنها نباید به خروجی نتایج اکتفا کنند بلکه باید نمودار خطا را هم بهعنوان بخشی از خروجی نمایش دهند. در علم، اگر شخصی اندازهگیریهای خود را بدون تخمین خطای مرتبط گزارش کند، هیچکس نتایج او را جدی نمیگیرد. نورد هم مانند بسیاری از پژوهشگران هوش مصنوعی نسبت به نفوذناپذیری نتایج شبکههای عصبی نگران است؛ اغلب اوقات، سیستم بدون ارائهی تصویری شفاف از چگونگی دستیابی به نتایج، تنها یک پاسخ را برمیگرداند.
بااینحال همه، عدم شفافیت را مشکل نمیدانند. لنکا دبوروا، پژوهشگر مؤسسهی فیزیک تئوری در CEA Saclay فرانسه، معتقد است نیتهای انسانی هم به همین اندازه غیرقابل نفوذ هستند. برای مثال انسان میتواند با نگاه کردن به تصویر یک گربه بهسرعت آن را تشخیص دهد. او حتی نمیداند چگونه به این اطلاعات پی برده است و مغز در اینجا نقش جعبه سیاه را ایفا میکند».
تنها اخترفیزیکدانان یا کیهانشناسان بهدنبال علم دادهمحور مبتنی بر هوش مصنوعی نیستند. فیزیکدانهای کوانتومی مثل راجر ملکو (از مؤسسهی فیزیک نظری پریمیتر و دانشگاه واترلوی انتاریو) از شبکههای عصبی برای حل بعضی از دشوارترین و مهمترین مسائل این حوزه مثل نمایش تابع ریاضی موج برای توصیف یک سیستم چند ذرهای استفاده کردهاند.
به عقیدهی ملکو دلیل اهمیت AI، مسئلهای به نام مشقت چندبعدی است. براساس این اصل، تعداد احتمالات شکل تابع موج بهصورت نمایی و براساس تعداد ذرات موجود در سیستم تابع رشد میکند. دشواری این مسئله مشابه تلاش برای جستجوی بهترین حرکت در بازیهایی مثل شطرنج یا Go است: در این بازیها معمولا بازیکن تلاش میکند حرکت بعدی را حدس بزند و رقیب را در حال بازی تصور کند، سپس بهترین واکنش ممکن را انتخاب میکند اما با هر حرکت تعداد احتمالات افزایش پیدا میکنند.
البته، سیستمهای هوش مصنوعی در هر دو بازی به مهارت رسیدند. پیروزی هوش مصنوعی بر انسان در بازی شطرنج به دهها سال قبل بازمیگردد؛ در مورد بازی Go، هوش مصنوعی با سیستمی به نام AlphaGO در سال ۲۰۱۶ موفق به غلبه بر یکی از بهترین رقیبهای انسانی شد. به عقیدهی ملکو این مسئله برای فیزیک کوانتومی هم صدق میکند.
ذهن ماشین
شاوینسکی هوش مصنوعی را روش سومی برای پژوهشهای علمی عنوان میکند اما هاگ معتقد است این روش، ترکیب روشهای سنتی تحلیل داده و مشاهده است. صرفنظر از اینکه ادعای کدام یک حقیقت دارد، تحولات و تأثیر هوش مصنوعی بر اکتشافات علمی و تسریع آنها بر کسی پوشیده نیست. اما تحولات هوش مصنوعی تا چه اندازه میتوانند بر علم تأثیر بگذارند؟
گاهی اوقات در مورد دستاورد دانشمندان رباتیک اغراق میشود. یک دهه پیش، دانشمند ربات هوش مصنوعی به نام آدام به بررسی ژنوم مخمر نانوایی پرداخت و به جستجوی ژنهایی پرداخت که مسئول تولید نوعی آمینواسید هستند. (آدام ازطریق مشاهدهی رشتهای از مخمرها که از ژن مشخصی محروم بودند این بررسی را انجام داد و سپس نتایج را با رفتار مخمرهای دارای این ژن مقایسه کرد). در آن زمان تمام اخبار تقریبا با این تیتر منتشر شدند: رباتی که بهتنهایی موفق به اکتشاف علمی شد

اخیرا لی کرانین، شیمیدان دانشگاه گلاسگو از ربات برای ترکیب تصادفی مواد شیمیایی استفاده کرده است تا به انواع ترکیبهای جدید برسد. سیستم مجهز به طیفسنجی جرمی، طیفسنجی مادونقرمز و ماشین رزونانس مغناطیسی هستهای است و در زمان واقعی با نظارت بر واکنشها، تشخیص میدهد کدام ترکیبها واکنشپذیرترند. بهگفتهی کرانین حتی اگر این روش، اکتشافات بیشتری را بهدنبال نداشته باشد، حداقل مزیت آن افزایش سرعت پژوهشها تا ۹۰ درصد است.
سال گذشته تیم دیگری از دانشمندان در مؤسسهی فدرال فناوری زوریخ از شبکههای عصبی برای استنتاج قوانین فیزیک از مجموعههای دادهای استفاده کردند. سیستم آنها یک نوع کپلر رباتیک بود که براساس اطلاعاتی مثل موقعیت خورشید و مریخ از دید ناظر زمینی، موفق به کشف مجدد مدل خورشیدمرکزی منظومهی شمسی شد و قانون حفظ تکانه را با نظارت بر توپهای نوسانگر محاسبه کرد. ازآنجاکه همیشه بیش از یک روش برای توصیف قوانین فیزیکی وجود دارد، پژوهشگرها هم در این سیستم بهدنبال روشهای جدیدی (شاید روشهای سادهتر) برای توصیف قوانین شناختهشده بودند.
تمام موارد فوق از نمونههای اکتشافات علمی هوش مصنوعی هستند که در هر نمونه میتوان در مورد میزان نوآوری و تحول روش جدید به بحث پرداخت. شاید جنجالیترین سؤال در این زمینه این باشد که چگونه میتوان حجم زیادی از اطلاعات را فقط از دادهها به دست آورد؟ جودیا پیرل و دانا مکنزی نویسندهی علمی، در کتابی با عنوان کتاب چرا (۲۰۱۸) معتقدند دادهها اساسا لال هستند. آنها مینویسند:
آیا میتوان سؤالهای مربوطبه رابطهی علت و معلولی را صرفا براساس دادهها پاسخ داد؟ اگر پژوهشی را دیدید که به تحلیل دادهها در مدلی پرداخته است، مطمئن باشید خروجی بررسی، خلاصه یا تبدیل دادهها است نه تفسیر آنها.
شاوینسکی با دیدگاه پیرل موافق است اما او معتقد است ایدهی کار فقط با دادهها کمی پوشالی است. شاوینسکی میگوید:
من هرگز مدعی استنتاج علت و تأثیر روش نشدم. بلکه معتقدم میتوانیم کارهای بسیار و فراتر از حد معمولی را با دادهها انجام دهیم.
براساس ادعایی دیگر، علم به خلاقیت نیاز دارد و حداقل تا امروز روشی برای برنامهنویسی خلاقیت در ماشین ابداع نشده است (صرفا رباتی مانند ربات شیمیدان کرانین که به آزمایش همهچیز میپردازد دلیلی بر اثبات این مدعا نیست). پولسترر میگوید:
قدرت نظریهپردازی و استدلال نیازمند خلاقیت است. هر بار به خلاقیت نیاز داشته باشید، به انسان نیاز دارید. اما سرچشمهی خلاقیت انسان کجاست؟ پولسترر معتقد است خلاقیت به ملالت یا خستگی مربوط است. ویژگیای که ماشین قادر به تجربهی آن نیست. برای خلاق بودن باید از کسالت یا خسته شدن گریزان باشید. به زبان ساده، حوصلهتان سر برود. و من فکر نمیکنم کسالت برای کامپیوتر معنایی داشته باشد.
از طرفی کلماتی مثل خلاقانه یا الهامبخش اغلب اوقات برای توصیف برنامههایی مثل Deep Blue و AlphaGo به کار میروند و توصیف آنچه در ذهن ماشین میگذرد انعکاسی از جستجوی فرآیندهای فکری انسان است.
شاوینسکی اخیرا در بخش خصوصی کار میکند و استارتاپی به نام Modulos را تأسیس کرده است. او تعدادی از دانشمندان ETH را استخدام کرده است و در قلب توسعههای هوش مصنوعی و یادگیری ماشین کار میکند. شاوینسکی و دانشمندان دیگر معتقدند، باوجود هر مانعی که بین هوش مصنوعی و ذهنهای مصنوعی تکاملیافته وجود دارد، ماشینها صرفنظر از هر محدودیتی برای انجام وظایف بیشتری آماده هستند. شاوینسکی میگوید:
آیا در آیندهای قابل پیشبینی ممکن است ماشینی ساخت که بتواند با سختافزار بیولوژیکی دست به اکتشافات فیزیک و ریاضی بزند که حتی از عهدهی انسانهای نابغه هم خارج باشد؟ آیا آیندهی علم درنهایت تحت کنترل ماشینها قرار میگیرد؟ ماشینهایی که میتوانند از عهدهی کارهای غیرممکن و غیرقابل دسترسی برای انسان برآیند؟ نمیدانم. درهرصورت سؤال خوبی است.

نظرات