داستان شهرت و دلیل علمی ویدیوی مشهور Yanny and Laurel



اگر تا امروز خبری در مورد ویدیوی مشهور «یانی و لارل» مشاهده نکرده یا ویدیوی آن را ندیدهاید، به ویدیوی این پست دقت کنید. چه صدایی میشنوید؟ آیا گوینده کلمهی Yanny را ادا میکند یا واژهی Laurel را میشنوید؟ اگر کلمهی دوم را میشنوید، از لحاظ فنی درست حدس زدهاید. اما بهراستی داستان این ویدیو از کجا شروع شد؟ در ادامهی این مطلب زومیت داستان شکلگیری و شهرت و دلیل علمی بروز چنین پدیدهای را مرور میکنیم.
تاریخچهی شهرت
داستانهای متعددی در مورد تاریخچهی شهرت این ویدیو وجود دارد. این فایل مانند تصویر منتشرشده در اینترنت در سال ۲۰۱۵، بحثهایی جدی در فضای مجازی داشت. تصویر سال ۲۰۱۵، یک لباس بود که برخی افراد آن را طلایی و برخی آبی میدیدند. محل اصلی انتشار صدایی که در ویدیو میشنوید، وبسایت Vocabulary.com بوده که این صوت را برای تلفط کلمهی Laurel (تاجی از برگ که بهعنوان نماد پیروزی بر سر گذاشته میشود) قرار داده بوده است.

همه چیز از تلفط کلمهی Laurel در وبسایت Vocabulary شروع شد
برخی منابع، این ویدیو را مربوط به سایت ردیت و سؤال یکی از کاربران آن میدانند. این سؤال در یکی از فرومهای سایت ردیت مربوط به پدیدههای غیر عادی منتشر شده است. پس از آن، ویدیو توسط کلو فلدمن یکی از کاربران پرطرفدار یوتیوب که بیش از ۶۱۰ هزار دنبالکننده دارد، در توییتر قرار گرفت.
حقیقت این است که انتشار ویدیوی یانی و لارل از ردیت شروع نشد. این ویدیو مانند بسیاری از پدیدههای این روزهای شبکههای مجازی، ریشه در گروههای نوجوانان دارد.
کیتی هتزل، دانشآموز سال اول دبیرستان فلاوری برنچ در جورجیا، در تاریخ ۱۱ می سال جاری در حال مطالعه برای کلاس ادبیات خود بود که با کلمهی Laurel رواجه شد. او برای آموختن معنی این کلمه به سایت Vocabulary رفت و معنای آن را جستجو کرد. وقتی کیتی برای درک تلفظ کلمه از قابلیت صوتی سایت استفاده کرد، بهجای تلفط لارل، کلمهی Yanny را شنید.
کیتی صدا را برای همکلاسیهای خود پخش کرد و از میان آنها، افراد مختلف صدای متفاوت شنیدند. او ویدیویی از این صدا ساخت و آن را در استوری اکانت اینستاگرام خود به نمایش گذاشت. نفر بعدی، فرناندو کاسترو یکی از دانشآموزان همان مدرسه بود که بهسرعت ویدیویی مشابه را در استوری خود منتشر کرد. در نهایت میتوان این دو نفر را منابع اصلی پخش شدن این ویدیو در اینترنت عنوان کرد. سپس یکی از دوستان کاسترو که این ویدیو برایش سؤالی عجیب ایجاد کرده بود، آن را از استوری کاسترو دریافت کرد و در فروم ردیت با نام کاربری RolandCamry به اشتراک گذاشت.
داستان ضبط صدا
داستان بالا تاریخچهی شهرت این ویدیو را نشان میدهد؛ اما سؤال بعدی این است که این صدا در اصل چگونه تولید شده؟ عموم افراد تصور میکنند که این یک صدای کامپیوتری است. اما در واقع این صدا در سال ۲۰۰۷ توسط یک خوانندهی اپرا ضبط شده است.
مارک تینکلر، مدیر فناوری و همبنیانگذار سایت Vocabulary، در اینباره میگوید: «این صدا داستانی خارقالعاده دارد. فردی که کلمه را تلفط میکند، یکی از اعضای گروه موسیقی Cats است.» او به این نکته اشاره میکند که در روزهای ابتدایی تأسیس وبسایت، آنها به دنبال افراد واقعی میگشتند تا کلمات را به بهترین نحو و بر اساس فونتیک معیار بینالمللی تلفظ کنند. نکتهی مهم این است که اکثر خوانندگان اپرا، بهخوبی این فونتیک معیار را میشناسند و تلفظ میکنند؛ چرا که آنها باید به زبانهای مختلف آواز بخوانند.

صدای این ویدیو کامپیوتری نیست و توسط یک خوانندهی اپرا ضبط شده است
تینکلر در ادامه از استخدام خوانندگان اپرا برای تلفظ ۲۰۰ هزار کلمه میگوید. البته او نام خوانندهی این صدا را فاش نمیکند؛ چرا که مطمئن نیست این خواننده از شهرت ایجادشده به خاطر این صدا استقبال کند. این فرد بیش از ۳۶ هزار کلمه را برای این سایت لغتنامه تلفظ کرده است.
همبنیانگذار وبسایت Vocabulary دلیل منطقیِ شنیدن صداهای مختلف توسط افراد گوناگون را درک نمیکند. البته او احتمال میدهد که دلیل این اتفاق، تلفظ کلمه در خارج از جمله است. او در مورد روند ضبط صداها میگوید: «ما لپتاپهایی مجهز به میکروفون قوی را در اتاقهای آکوستیک قرار دادیم و کلمات را به ترتیب به خوانندهها نشان دادیم. آنها نیز هر کلمه را بهصورت مجزا تلفظ و ضبط کردند.»
دلیل علمی
خوشبختانه دانشمندان دلیلی علمی برای این پدیده دارند. برخی از این دانشمندان سعی کردند در توییتر دلیل این پدیده را توضیح دهند. آنها این کلیپ ویدیویی را یک پدیدهی خطای تشخیص مانند خطای دید عنوان میکنند. یک دانشمند عصبشناسی نیز در مقالهای در وبسایت ورج، این پدیده را شبیه به خطای دید گلدان رابین توصیف کرده است. در این خطای دید، برخی افراد تصویر دو چهره و برخی دیگر یک گلدان گل میبینند.

در تعریف ساده، این پدیده یک «خطای دید» برای گوشهای افراد است! در نهایت، تعریف کاملی از دلیل وقوع این پدیده وجود ندارد و نمیتوان پاسخی کاملا صحیح برای آن پیدا کرد. یکی از دلایل اصلی وجود اختلافات زیاد در مورد شنیدن صداها، وجود نویز و فرکانسهای زیاد در این فایل صوتی است. به بیان دیگر تفاوت در شنیدن کلمات، به توانایی افراد در شنیدن فرکانسها مربوط است.
فرکانسهای بالا در فایل صوتی باعث میشو افراد کلمهی Yanny را در این فایل بشنوند و کلمهی Laurel نتیجهی فرکانسهای پایین است. در تعریف علمی، آنچه میشنویم به تمرکز مغز روی صداها وابسته است. علاوه بر آن تجربیات گذشته و آنچه انتظار داریم بشنویم، باعث شنیدن کلمهی متفاوت میشود. دلیل دیگر، سن افراد است. افراد مسنتر عموما بهمرور توانایی شنیدن فرکانسهای بالا را از دست میدهند و به همین دلیل جوانها بیشتر کلمهی Yanni را میشنوند.
وبسایت مجلهی نیویورک تایمز ابزاری تهیه کرده که فرکانسهای مختلف این فایل صوتی را تقویت میکند. کاربر با تغییر دادن ابزار کشویی در این وبسایت به سمت کلمههای Yanny یا Laurel میتواند هر دو کلمه را در یک فایل صوتی بشنود. این ابزار نشان میدهد که هر فرد تا چه حد در شنیدن فرکانسهای بالا یا پایین قوی است.
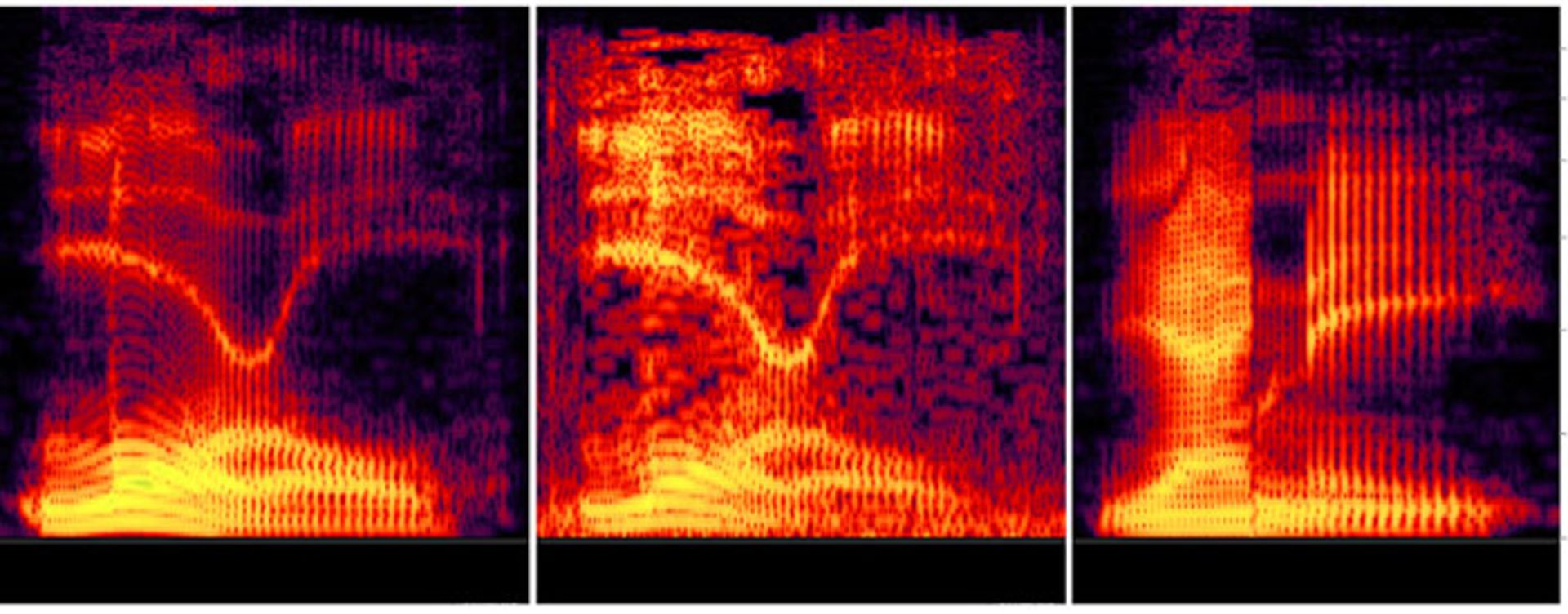
در تصویر بالا، مقایسهی فنی فرکانسهای ایجاد شده توسط این ابزار را مشاهده میکنید. تصویر سمت چپ مربوط به حالتی است که فرکانسهای پایین تقویت شدهاند، تصویر میانی مربوط به فایل اصلی تصویر سمت راست حالتی است که فرکانسهای بالا با ترکیب تلفظ کلمات Yangtze و Uncanny تقویت شدهاند. با دقت در طیف تصویر متوجه میشویم که تصویر کلمهی لارل در فرکانسهای پایین قویتر است و کلمهی یانی، فرکانسهای بالایی قوی دارد. این در حالی است که طیفنگارهی فایل صوتی اصلی، ترکیبی از هر دو را دارد و شنیدن طیف فرکانسها به گوش شنونده وابسته است.
دلایل فنی هم برای شنیدن صداهای مختلف وجود دارد. شنیدن کلمه به اسپیکر، هدفون و حتی حالت آکوستیک پخش فایل بستگی دارد. یک دانشجوی PhD دانشگاه MIT در توییتر خود در این مورد نوشته است: «دلیل اصلی شنیدن کلمات مختلف، فیلتر کردن متفاوت فرکانسها توسط هدفونها و اسپیکرهای گوناگون است.» این دانشجوی دکترا، دانا بوبینگر نام دارد و در زمینهی ادراک شنوایی تحصیل میکند. یکی از دلایل فنی دیگر، به پلتفرمی بازمیگردد که برای بار اول، صدا را از آن شنیدهاید. این اختلاف به تفاوت توییتر و اینستاگرام در فشردهسازی ویدیوها نیز وابسته است.

نظرات