انویدیا با معرفی Pascal و NVLink و حافظهی سه بعدی، نقشه راه کارت گرافیکهای خود را بروز کرد

امسال در نشست سالانهی تکنولوژیهای کارت گرافیک، انویدیا مثل همیشه به معرفی نقشه راه خود و نمایشی از روند صعودی پیشرفت معماریهای خود پرداخت. در GTC 2013 انویدیا از معماری Volta صحبت کرد. همانطور که میدانید معماری فعلی کارت گرافیکهای سری 700 انویدیا، Kepler نام دارد. کمی پیشتر با معرفی دو کارت گرافیک رده متوسط و پایین GTX 750 و GTX 750 Ti شاهد رونمایی از اولین تراشههای مبتنی بر معماری Maxwell بودیم که در زومیت به بررسی عمیق آن پرداختیم.
کپلر و مکسول هر دو از دانشمندان بزرگ بودند و معماری بعدی که ولتا نام دارد هم نام یکی دیگر از دانشمندان است که شاید در علم فیزیک و واحد اختلاف پتانسیل الکتریکی یعنی ولت، نامش را شنیده باشید.
فعلاً در مورد زمانبندی برای رونمایی از محصولات مبتنی بر ولتا خبری منتشر نشده ولیکن برای مکسول برنامهریزی روشن شده است.
مکسول و ولتا، دو معماری بعدی انویدیا
طبق نمودار زیر هر یک از معماریها با یک شاخص معرفی شدهاند، کپلر که معماری فعلی است، قابلیت موازیسازی پویای امور محوله را دارد. مکسول هم با این ویژگی معرفی شده: حافظهی مجازی یکپارچه. برنامهی انویدیا هم این است که مکسول را تا اواخر سال 2014 کاملتر روانهی بازار کند.
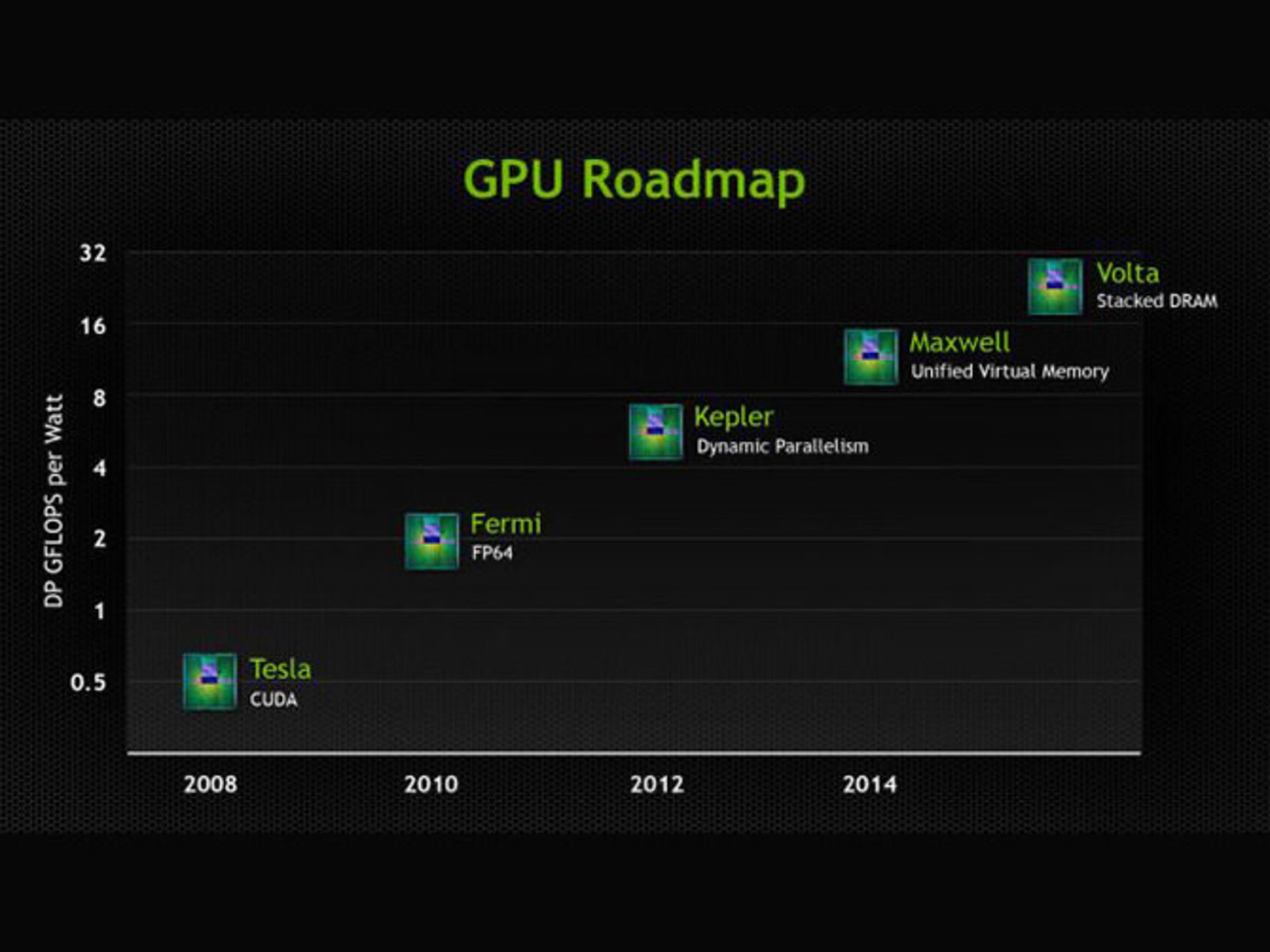
در مورد ولتا ویژگی اساسی حافظهی DRAM داخلی است، منظور از داخلی این است که حافظه با استفاده از فناوری TSV یا Through Silicon Via روی قالب تراشهی پردازندهی گرافیکی شکل بگیرد.
وقتی مکسول و ولتا در عمل با مشکل مواجه میشوند، پاسکال ظهور میکند
اما انویدیا در عمل ویژگی مکسول را به سرانجام نرسانده و قرار است آن را بعدها در معماریهای بعدی کامل کند. فعلاً تنها اتفاقی که در عمل شاهد هستیم، پشتیبانی از حافظهی مجازی یکپارچه به صورت نرمافزاری است که در CUDA 6 عملی شده است. علاوه بر این انویدیا هنوز در مورد نسل دوم مکسولها صحبتی نکرده و مشخص نیست که کارت گرافیکهای مکسولی رده اول، تا چه حد قدرتمند و سریع خواهند بود.
در نمودار زیر میبینیم که در نقشه راه جدید انویدیا، ویژگی اساسی مکسول پشتیبانی از DX 12 ذکر شده است.
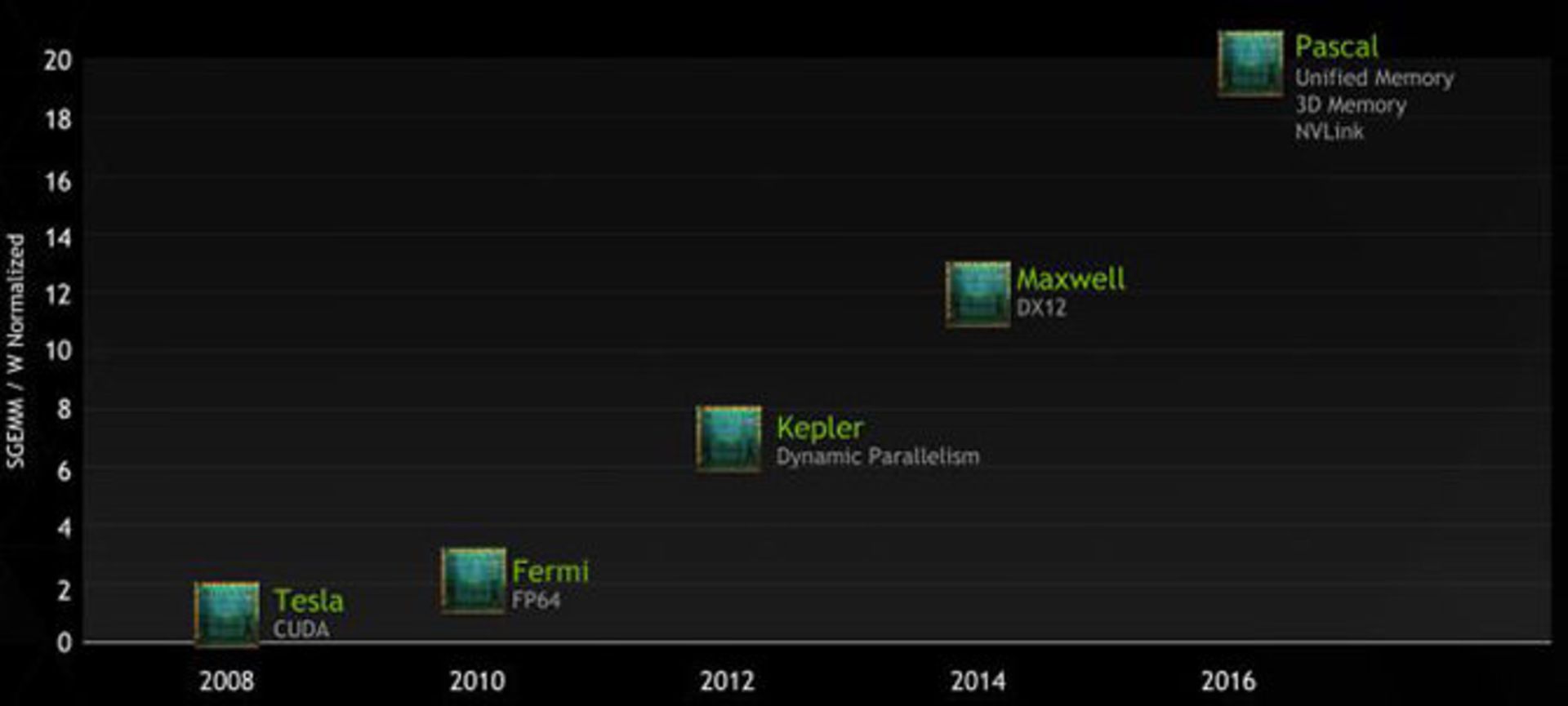
مکسول با معرفی کارت گرافیک GTX 750 شروع کرده و قرار است در سال 2014 تدریجاً سایر مدلها معرفی شوند. اما آنچه باعث نا امیدی است، فقدان قابلیتهای جدیدی است که به قابلیتهای خانوادهی موفق کپلر (سری 700) و نسل اول مکسولیها اضافه شود.
تغییر دیگر در نقشه راه به ولتا مربوط میشود، خبری از نام آن نیست! هنوز مشخص نشده که چرا ولتا در این نقشه راه دیده نمیشود اما آنچه قطعی به نظر میرسد، عرضه شدن آن دیرتر از زمانبندیهایی است که قبلاً اعلام شده بود. ویژگی اساسی ولتا هم زیر نام معماری Pascal ذکر شده که خود عجیب به نظر میرسد.
فعلاً برنامهی انویدیا عرضهی پاسکال در سال 2016 به بعد است، پاسکال دو ویژگی اساسی که قبلاً برای مکسول و ولتا ذکر شده بود را جذب کرده و یک معماری جدید و بسیار جالب به نظر میرسد.
پاسکال در نگاه اول
انویدیا برای بهبود عملکرد تراشههای گرافیکی خود، تصمیم گرفته که با استفاده از TSV، حافظههای DRAM را روی تراشهها اضافه کند. خبر جدید در این رابطه این است که انویدیا طبق یکی از استانداردهای معرفی شده توسط JEDEC به نام HBM استفاده میکند. HBM مخفف High Bandwidth Memory به معنی حافظههایی با پهنای باند بالاست. در نمونهای که انویدیا تولید کرده هم تمام حافظهی کارت گرافیک پاسکالی به صورت مجتمع بوده و هیچ حافظهی دیگری روی کارت گرافیک وجود ندارد.

قبلاً در معرفی ولتا از پهنای باند 1 ترابایت در ثانیه صحبت شده بود ولیکن در مورد پاسکال هیچ عدد خاصی ذکر نشده است.
یک مشکل جدی در رابطه با این حافظهها، هزینهی تولید است، باید صبر کرد و دید که در قبال پهنای باند بالاتر، چه هزینهای متوجه مشتریان انویدیا خواهد بود.

NVLink چیست؟ چه اثری روی پهنای باند و رابطهی بین پردازندهی اصلی و گرافیکی دارد؟
انویدیا در نشست اخیر در مورد حافظهی مجازی یکپارچه اطلاعات جدیدی منتشر نکرده است اما یک ویژگی جالبتر به نام NVLink را معرفی کرده است.
برای ارتباط بین پردازندهی اصلی و گرافیکی از باسی به نام PCI Express استفاده میشود که در مادربوردهای جدید با نسخهی سوم آن روبرو هستیم. این واسط ارتباطی به ازای هر Lane پهنای باندی معادل 985 مگابایت در ثانیه دارد. توجه کنید که منظور از Lane یک مسیر دو جهته برای دریافت و ارسال سیگنال به صورت تفاضلی است. لذا در مورد مادربوردهای متداول امروزی، اگر تعداد مسیرها 16 عدد باشد و یا به اصطلاح بازاری، پهنای شکاف PCI Express، به صورت x16 نوشته شود، پهنای باند این اسلات مادربورد، 16 ضرب در 0.985 گیگابایت یا حدود 16 گیگابایت در ثانیه خواهد بود.
کارت گرافیکهای مدرن امروزی پهنای باند حافظهای به مراتب بالاتر از محدودیتهای موجود مثل ارقام بالاتر از 250 گیگابایت در ثانیه دارند. البته این رقم پهنای باند حافظهی روی کارت گرافیک است و قرار نیست واسط ارتباطی PCI-Express هم به همین اندازه سرعت داشته باشد. ولیکن 16 گیگابایت بر ثانیه و حتی 31.5 گیگابایت در ثانیهای که با معرفی نسل چهارم واسط PCIe حاصل شده، به نظر کافی نیستند.
NVLink برای حل همین مشکل معرفی شده و قرار است یک جایگزین خوب برای PCIe باشد. ساختار NVLink به شدت شبیه PCIe است و حتی درست مثل آن پروگرم میشود. اما تفاوت اصلی آن طراحی برای ارتباط بهتر نقطه به نقطه است. NVLink هم سیگنال را به شکل تفاضلی منتقل میکند و کوچکترین واحد ارتباطی در آن بلوک نام دارد. یک بلوک یا Block، شامل 8 مسیر یا همانطور که قبلاً توضیح داده شد، 8 لِین است. هر مسیر پهنای باندی معادل 20 گیگابیت در ثانیه دارد، لذا اگر پهنای واسط ارتباطی به اندازهی 8 مسیر باشد، پهنای باند حاصل شده، 20 گیگابایت در ثانیه (160 گیگابیت در ثانیه) خواهد بود. توجه کنید که در PCIe 3.0 هر مسیر حدود 8 گیگابیت در ثانیه سرعت داشت. یعنی سرعت حدود 2.5 برابر بیشتر است.
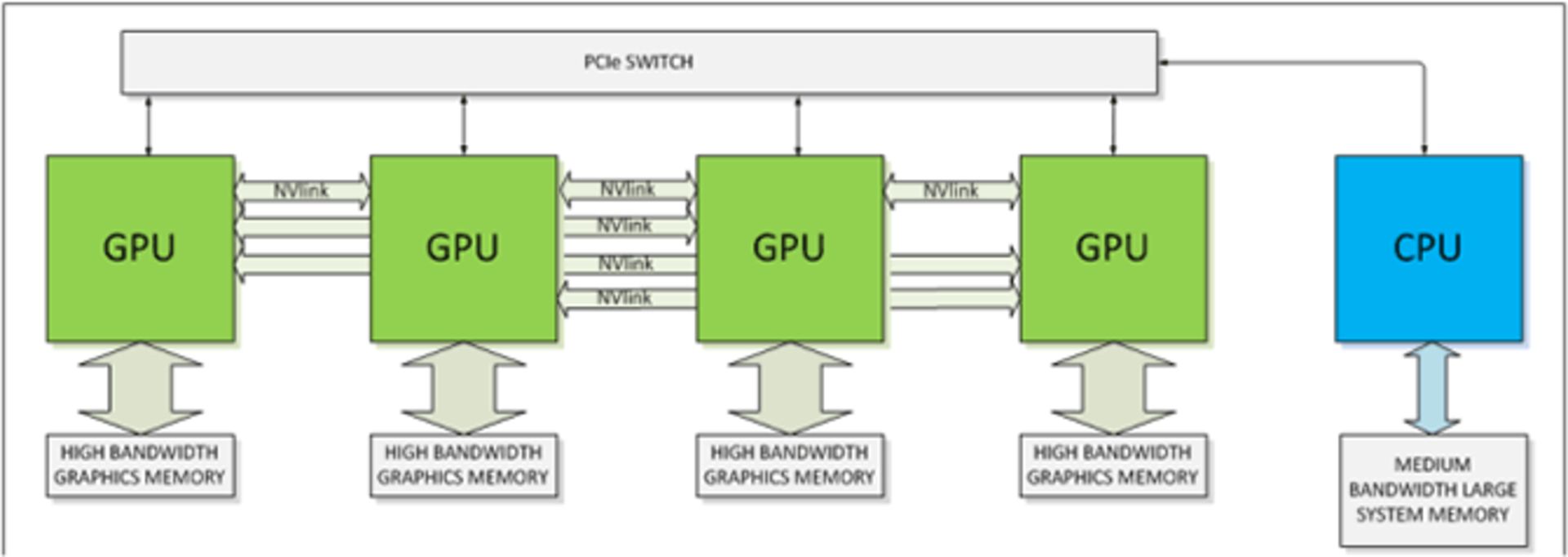
برای ارتباط بهتر میتوان چند بلوک را با هم ترکیب کرد تا رابطهی بین دو ابزار خاص سریعتر شود، امکان دیگر رابطه با ابزارهای اضافی دیگر است. به بیان دیگر برای ارتباط ابزارها با هم، نیازی به ارتباط با ریشهی شکافها و استفاده از یک سوییچ مجزا نیست. به استفاده از ریشهی مرکبی که در پردازندهی اصلی گنجانده شده هم نیازی نیست، به همین علت است که میگوییم NVLink یک واسط با طراحی کاملاً نقطه به نقطه است و ابزارهای متصل و به عبارتی پردازندههای گرافیکی مستقیماً با هم در ارتباط خواهند بود.
اما به شباهت NVLink با Hypertransport کمپانی رقیب یعنی AMD و همچنین ارتباط داخلی Quick Path Interconnect اینتل توجه کنید، همگی به این ویژگی NUMA اشاره دارد که نیازی نیست تمام پردازندهها با هم در ارتباط باشند. NUMA یا دسترسی غیریکنواخت به حافظه، روشی است که در آن یک پردازنده دسترسی بهتری به حافظهی اختصاصی خود دارد.
کارت گرافیکهای آینده، عمود بر مادربورد نخواهند بود؟
NVLink پهنای باند بالایی دارد و انویدیا برای ایجاد چنین سرعت فوقالعادهای نمیتواند از PCI و PCIe استفاده کند. طول واسط ارتباطی باید کوتاهتر باشد. بنابراین انویدیا تصمیم گرفته به جای استفاده از اسلاتهای شبیه PCIe روش دیگری اتخاذ کند.
انویدیا نام کانکتور جدید را درست شبیه اتصال دو برد مدار چاپی (یا PCB) در نظر گرفته که در کارت گرافیک دو هستهای GTX 295 شبیه آن را دیده بودیم. mezzanine روشی برای چسباندن دو PCB است که انویدیا همین عنوان را انتخاب کرده است.


البته هنوز هیچ کانکتور خاصی معرفی نشده ولیکن چنین روش جدیدی به اعمال تغییرات جدی در مادربورد نیاز دارد و در واقع مادربوردهایی که از NVLink پشتیبانی میکنند، باید طراحی متفاوتی داشته باشند. اما مزیت مهم روش جدید این است که همانطور که گفته شد، طراحی کاملاً نقطه به نقطه خواهد بود، به علاوه پردازندهی گرافیکی هم مثل CPU اتصالی شبیه سوکت خواهد داشت و مدارات مربوط به تأمین توان مصرفی و ارتباط با حافظه، روی تراشهی گرافیکی ایجاد میشوند.
نمونهای که انویدیا از پاسکال رونمایی کرده، در تصویر زیر دیده میشود:

کانکتور در این تصویر مشخص نیست ولیکن روش اتصال قرار گرفتن روی مادربورد است و مثل کارت گرافیکهای فعلی، به صورت عمودی قرار نمیگیرد.
یک مزیت دیگر روش جدید انویدیا این است که میتوان برای خنککاری، مثل پردازندهی اصلی عمل کرد، البته این موضوع در مورد سرورها اهمیت دارد نه دستاپهای معمولی چرا که فضای در دسترس، در مورد سرورها بسیار مهمتر از دستاپهاست. برای هر کارت گرافیک با طراحی جدید، یک کانکتور NVLink لازم است.
در تصویر زیر یک کانکتور اصطلاحاً mezzanine با پهنای باند بالا را مشاهده میکنید:

آخرین مزیت کاکنتور مِزنین مانند NVLink این است که در انتقال و تحویل توان مصرفی، بازدهی بالاتری دارد. در واقع بنابر ادعای انویدیا، انرژی لازم برای انتقال هر بایت داده، کمتر از PCIe است. علاوه بر این محدودیت انتقال توان در NVLink بیش از 75 واتی است که در مورد PCIe تعریف شده است، لذا استفاده از کارت گرافیکهای قویتر بدون نیاز به کابل 6 یا 8 پین سادهتر خواهد شد.
آیندهی NVLink و طراحی کارت گرافیکها
NVLink از نظر پهنای باند و نوع طراحی بهینهتر از PCIe است ولیکن جایگزینی PCIe در ابعاد بزرگ به این سادگیها نیست. در واقع بلوکهای ارتباطی که انویدیا تعریف کرده، از طریق PCIe هم قابل پیادهسازی هستند، درست مثل تصویر زیر:
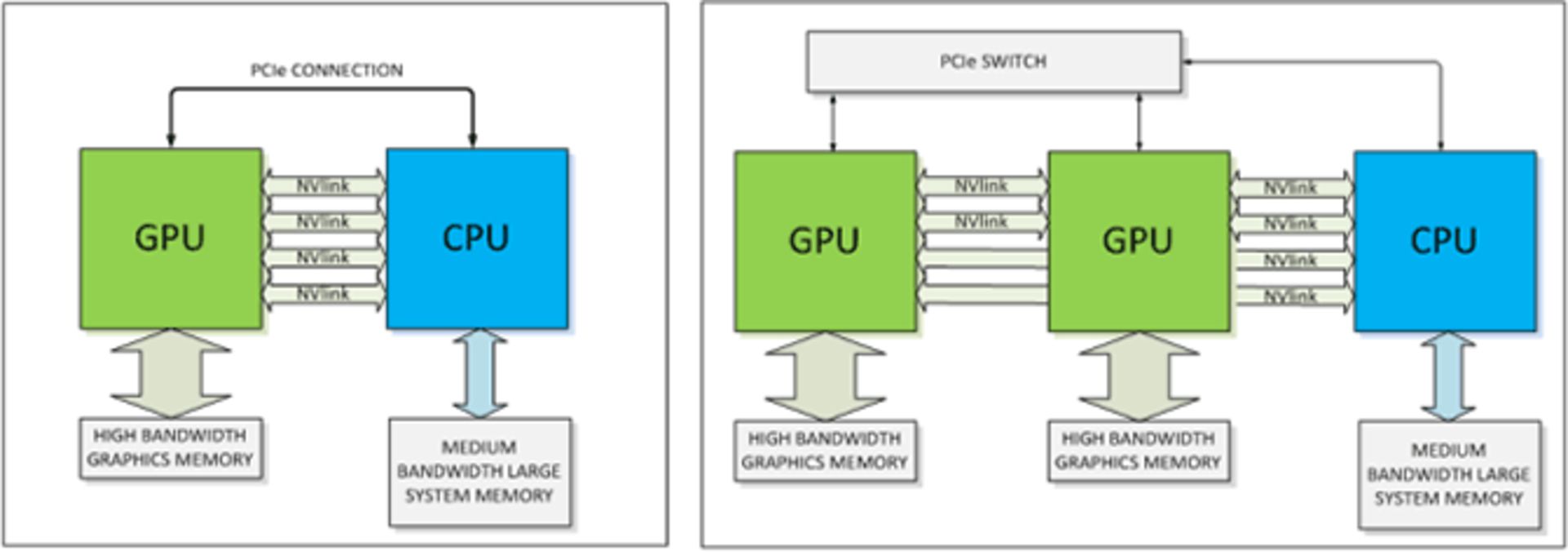
موضوع دیگر این است که در استفاده از NVLink هم باید برخی دستورات و ارتباطات همچنان از طریق PCIe ارسال و برقرار شوند.
بنابراین در نقشه راه انویدیا، استفاده از PCIe همچنان پابرجاست. لذا انویدیا مجبور است فعلاً از PCIe هم استفاده کند. بهترین پیشبینی در مورد آیندهی NVLink این است که در سرورها مورد استفاده قرار بگیرد و کاربران عادی از همان PCIe معروف بهره ببرند.
به هر حال تا سال 2016 هنوز 2 سال زمان باقیمانده و فعلاً خبری از پاسکال و NVLink نیست. NVLink قرار است چندین پردازندهی گرافیکی را طوری به هم مربوط کند که گویی همگی یک پردازندهی واحد هستند.
در حال حاضر NVLink به عنوان بخشی از کنسرسیوم OpenPOWER در اختیار طراحان POWER CPU قرار گرفته ولیکن هنوز هیچ پردازندهی خاصی اعلام نشده است. حتی این احتمال هم وجود دارد که انویدیا از پردازندههای مبتنی بر ARM برای پیادهسازی NVLink استفاده کند، شاید Denver که نام هستههای 64 بیتی تراشهی تگرا کیوان است هم به این منظور به کار گرفته شود. فعلاً هیچ خبری در این رابطه منتشر نشده است.
بنابر اظهارات انویدیا، نسخهی دوم NVLink برای معماری پس از پاسکال که احتمالاً ولتا باشد، در نظر گرفته شده و در آن حافظهی کش با واسط و پردازندهای که روی آن است، یکی شده و ارتباط بهینهتر و سریعتری دارد و در ضمن در اجرای منسجمتر دستورات مطابق با معماری ناهمگن سیستم (HSA) گامی رو به جلو است.


نظرات