OCR چیست و چگونه کار میکند؟



تبدیل کردن کاراکترهای چاپی یا متنهای دستنویس به فایلهای دیجیتال و قابل درک در کامپیوتر، فرایند پیچیدهای دارد. درواقع نیاز به فناوریهایی که بهطور کلی ارتباط بین کامپیوترها و انسانها و درک زبانها را آسان کنند، نیاز همیشگی در عصر کامپیوتر بودهاند. اغلب کامپیوترها برای درک خواستههای ما به ورودیهای مرسوم از دستگاههایی همچون ماوس و کیبورد نیاز دارند. ازطرفی ما برخی اوقات به وارد کردن اطلاعات از کتاپهای چاپی قدیمی یا دستنوشتههای خاص به کامپیوترها داریم. در چنین مواردی کامپیوتر برای درک ورودی به ابزارها و راهکارهای پیچیدهتری نیاز پیدا میکند. در چنین مواردی، فناوری تشخیص کاراکتر نوری (یا اپتیکی) موسوم به OCR وارد عمل میشود.
فناوری OCR به زبان ساده نرمافزاری است که بهصورت خودکار، متن چاپ شده را تحلیل کرده و آن را به فرمی تبدیل میکند که کامپیوتر بهراحتی توانایی پردازشش را داشته باشد. فناوری مذکور امروزه در بسیاری از تجهیزات دنیای فناوری استفاده میشود. از برنامههای تحلیل دستخط تا گوشیهای هوشمند و دستگاههای عظیم مدیریت و دستهبندی مرسولههای پستی، امروزه از OCR بهره میبرند. اگر بهدنبال پاسخ به این سؤال هستید که چگونه متن چاپی با OCR به کاراکتر دیجیتالی تبدیل میشود، با زومیت همراه باشید.
OCR چیست؟
وقتی مشغول مطالعه متن این مقاله هستید، چشمها و مغز شما فرایندهای تشخیص کاراکتر اپتیکی را انجام میدهند و حتی متوجه چنین فرایندی نمیشوید. چشمها، الگوهای روشن و تاریکی که کاراکتر را تشکیل میدهند، شناسایی میکنند (حروف، اعداد یا علائم نگاری و موارد مشابه، همگی کاراکتر هستند). سپس مغز شما از دادههای دریافتشده، اطلاعات میسازد و متن را تحلیل و درک میکند. ساختن اطلاعات برخی اوقات با اسکن تک به تک حروف و برخی اوقات با اسکن کامل کلمه یا جمله رخ میدهد.
کامپیوترها هم میتوانند عملکردی شبیه به چشم و مغز داشته باشند، اما قطعا کار پیچیدهای در پیش دارند. مشکل اصلی این است که کامپیوترها چشم ندارد. درنتیجه برای خواندن متنی مثلا از یک کتاب قدیمی، باید عکس دیجیتالی آن را ازطریق ابزارهای مرسوم مانند اسکنر یا دوربین دیجیتال دراختیار کامپیوتر قرار دهید. صفحهای که با استفاده از ابزارهای ثبت عکس ایجاد میشود، در دستهی محتوای گرافیکی قرار میگیرد. کامپیوتر در ابتدا هیچ تفاوتی بین این تصویر یا هر فایل گرافیکی دیگر (اغلب با فرمت JPG) مانند تصاویر منظره یا اشخاص قائل نمیشود. به بیان دیگر، کامپیوتر بهجای متن موجود در صفحه، «عکسی» از آن را دراختیار دارد و قطعا نمیتواند بهراحتی ما، متن موجود در عکس را بخواند. OCR برای تبدیل کردن عکس متن به یک متن واقعی استفاده میشود. به بیان دیگر با استفاده از OCR میتوانید از عکس گرفتهشده از یک صفحهی کتاب، فایل TXT یا DOC یا هر فرمت متنی دیگر تولید کنید.

مزیتهای OCR
وقتی یک تصویر دارای متن، به متنی قابل ویرایش در کامپیوتر تبدیل شود، قابلیتهای بسیار زیادی دراختیار شما قرار میگیرد. از مزیتهای بسیار مهم میتوان به جستوجوی کلمه در میانهی متن اشاره کرد. قابلیت دیگر در ویرایش دیده میشود. میتوانید آن متن را بهراحتی در بک صفحهی وب استفاده کنید. فشردهسازی، جابهجایی آسانتر، ذخیره در سرویسهای ابری و بسیاری کاربردهای دیگری که با هر فایل متنی دیجیتالی انجام میشود، با فایل استخراجشده بهکمک OCR هم قابل اجرا خواهد بود. یکی از کاربردهای مهم، تبدیل متن به صوت در کامپیوتر است. تصور کنید که یک کتاب قدیمی با OCR به متن دیجیتالی تبدیل میشود و سپس بهراحتی کامپیوتر آن را با صدای پیشفرض میخواند که خصوصا برای کاربران نابینا بسیار مفید خواهد بود. یکی از اولین کاربردهای OCR در دههی ۱۹۷۰ بود که دستگاهی شبیه به فتوکپی بهنام Kurzweil Reading Machine، با اسکن کردن کتابهای چاپی، آنها را برای کاربران نابینا میخواند.
OCR چگونه کار میکند؟
تصور کنید که در کل جهان تنها یک زبان و یک حرف وجود داشت: حرف A. حتی در چنین وضعیتی هم استفاده از OCR در کامپیوترها با چالشهای گوناگون روبهرو میشد، چون افراد متفاوت، شیوهی نوشتن منحصربهفردی برای نگارش همان یک حرف دارند. حتی در متنهای چاپشده هم مشکلات زیادی داریم. بههرحال هر متن یا کتاب چاپ شده با فونتی منحصربهفرد و حتی تفاوت در رنگ و چاپ، منتشر میشود.
برای حل چالش تفاوت در نوشتار، دو راهکار اصلی وجود دارد. یکی از راهکارها از شناسایی کامل کاراکتر استفاده کرده، یعنی الگوی آن را شناسایی میکند. راهکاری دیگر، خطوط تکی کاراکتر را مورد تحلیل قرار میدهد که به شناسایی براساس مشخصه هم شهرت دارد.
شناسایی الگو
اگر همهی افراد و ناشران، حرف تکی A را به یک صورت مینوشتند و چاپ میکردند، شناسایی آن در کامپیوتر دشوار نبود. درواقع تنها باید یک تصویر از A را در کامپیوتر ذخیره کرده و سپس هر کاراکتر اسکن شده را با آن مقایسه میکردیم. اگر دو کاراکتر، شبیه به هم بودند، کاراکتر اسکن شده بهعنوان حرف A بهصورت متن دیجیتالی ثبت میشد.
چگونه همهی مردم را به نوشتن به یک شکل ملزم کنیم؟ در دههی ۱۹۶۰، فونتی بهنام OCR-A توسعه یافته بود که روی اسناد مهمی همچون چکهای بانکی استفاده میشد. هریک از حروف، عرض برابری با دیگری داشت و فضای برابری را اشغال میکرد (فونت Monospace). خطوط حرفها نیز بهگونهای طراحی شده بود که بهراحتی بتوان هر حرف را از دیگری تشخیص داد. پرینترهای مخصوص چک، همگی از فونت مذکور استفاده میکردند و درنهایت دستگاههای اسکن OCR نیز امکان شناسایی و تحلیل آن را داشتند. درنهایت با استاندارد کردن یک فونت ساده، حل کردن مشکل OCR هم تسهیل شد.
راهکار فونت OCR-A قطعا برای همهی شرایط کاربرد ندارد. همهی ناشران و نویسندهها از فونت مذکور استفاده نمیکنند و دستخط کاربران نیز قطعا شبیه به چنین فونتی نیست. قدم بعدی، یاد دادن فونتهای مرسوم دیگر به برنامههای OCR بود. از فونتهای مرسوم میتوان به Times, Helvetica, Courtier و دیگران اشاره کرد. با پیشرفت فناوری، OCR توانایی تشخیص اغلب متنهای چاپشده را پیدا کرده بود، اما باز هم تا تشخیص همهی ورودیها فاصلهی زیادی داشت.

فونت OCR-A
شنسایی براساس مشخصه
روش دیگر شناسایی با OCR که روندی پیچیده دارد، بهنام Intellgent Character Recognition یا ICR هم شناخته میشود. تصور کنید که تعداد زیادی حرف را با فونتهای گوناگون به برنامهی OCR ارائه کنیم. برای شناسایی چنین تنوعی از حروف و کاراکترها، نیاز به رویکردی پیچیدهتر داریم. بهعنوان مثال برای همان حرف A باید به کامپیوتر بگوییم که هرگاه دو خط زاویهدار در نقطهای در بالا و مرکز به هم میرسند و یک خط افقی هم تقریبا از میانهی آنها عبور میکند، حرف A را میبینیم. قطعا چنین قانونی صرفنظر از فونت و دستخط، برای حرف A صادق میشود و میتوان همین قانون را برای حروف دیگر در زبانهای دیگر پیادهسازی کرد.
کامپیوتر با یادگیری مشخصههای زاویه و خطوط کاراکتر، آن را شناسایی میکند
در روش شناسایی براساس مشخصه، بهجای گشتن بهدنبال الگوی مشترک بین حروف ورودی با الگوی ثابت حروف، بهدنبال مشخصههایی همچون خطوط زاویهدار، خط افقی قطع کننده، انحنای خطوط و مواردی اینچنینی هستیم که حروف را از هم متمایز میکند. اکثر برنامههای OCR مدرن با پشتیبانی از فونتهای گوناگون، بهجای سیستمهای شناسایی الگو از شناسایی مشخصه بهره میبرند. نمونههای پیشرفتهتر هم شبکههای عصبی را بهکار میگیرند تا تشخیص دقیقتری داشته باشند.
الگوریتمهای تشخیص دستخط چگونه عمل میکنند؟
شناسایی کاراکترهایی که با پرینترهای باکیفیت لیزری یا دستگاههای چاپ حرفهای روی کاغذ نقش بستهاند، نسبت به شناسایی دستخط افراد بسیار آسانتر است. در بررسی و شناسایی متن از میان دستخطها، انسانها تواناییهای بسیار بهتری نسبت به کامپیوترها دارند. ما روزانه حتی با خواندن بدترین دستخطها هم امکان استخراج مفهوم و منظور نوشته را داریم. مغز انسان از ترکیبی از تشخیص الگوی خودکار، استخراج مشخصه و (قطعا) اطلاعات پیرامون نویسنده و معنا و مفهوم متن استفاده میکند تا دستخط نوشته شده را شناسایی کند. اگر کامپیوتر بخواهد چنین ترکیبی را در OCR به کار بگیرد، قطعا پیچیدگیهای زیادی در پیش رو خواهد داشت. در ادامه، مراحل تشخیص دستخط در OCR را بررسی میکنیم:
آسانسازی
وقتی برای تشخیص دستخط به کامپیوترها نیاز پیدا میکنیم، عموما مسائل را بهصورت سادهتر به آنها ارائه خواهیم کرد. بهعنوان مثال، ماشینهایی که برای دستهبندی مرسولههای پستی استفاده میشوند، تنها وظیفهی شناسایی کاراکترهای موجود در کد پستی را دارند و کل آدرس را اسکن نمیکنند. درنتیجه چنین کامپیوترهایی تنها باید یک متن کوتاه را شناسایی کنند که از تعداد محدودی کاراکتر تشکیل شده است. ازطرفی قوانین پست هم از کاربران میخواهد که آدرسها و کاراکترها را طبق دستورالعمل مشخصی وارد کنند. بهعنوان مثال حروف باید در بخشهای مشخصی از آدرس و با فاصلهی مناسب نوشته شوند.
اسناد رسمی که نیاز به اسکن شدن و تبدیل شدن به فایل دیجیتال بهکمک OCR دارند، اغلب بهصورتی طراحی میشوند که کاربر، حروف را با دقت در آنها وارد کند. حتما با اسنادی روبهرو شدهاید که باید نام و نام خانوادگی و اطلاعات دیگر را بهصورت حروف جدا از هم در مربعهایی مشخص در آنها وارد کنید. این اسناد اغلب با رنگ پسزمینهی خاصی هم چاپ میشوند تا بیشترین تفاوت تم رنگ را با نوشتهها داشته باشند. بهعنوان مثال رنگی همچون صورتی انتخاب میشود که درصورت نوشتن متن با جوهر مشکی یا آبی، تفاوت کامل را ایجاد کند.
گوشیهای هوشمند و تبلتهایی که قابلیت تشخیص دستخط دارند، اغلب از رویکرد شناسایی مشخصه بهره میبرند. بهعنوان مثال وقتی کاربر مشغول نوشتن حرف A میشود، دستگاه تمامی فعالیتهای او را در کشیدن خطوط دنبال میکند و کاراکتر را تشخیص میدهد. درنتیجه در تشخیص دستخط از نمایشگرهای لمسی، استفاده از رویکرد مشخصه آسانتر و کاربردیتر خواهد بود.
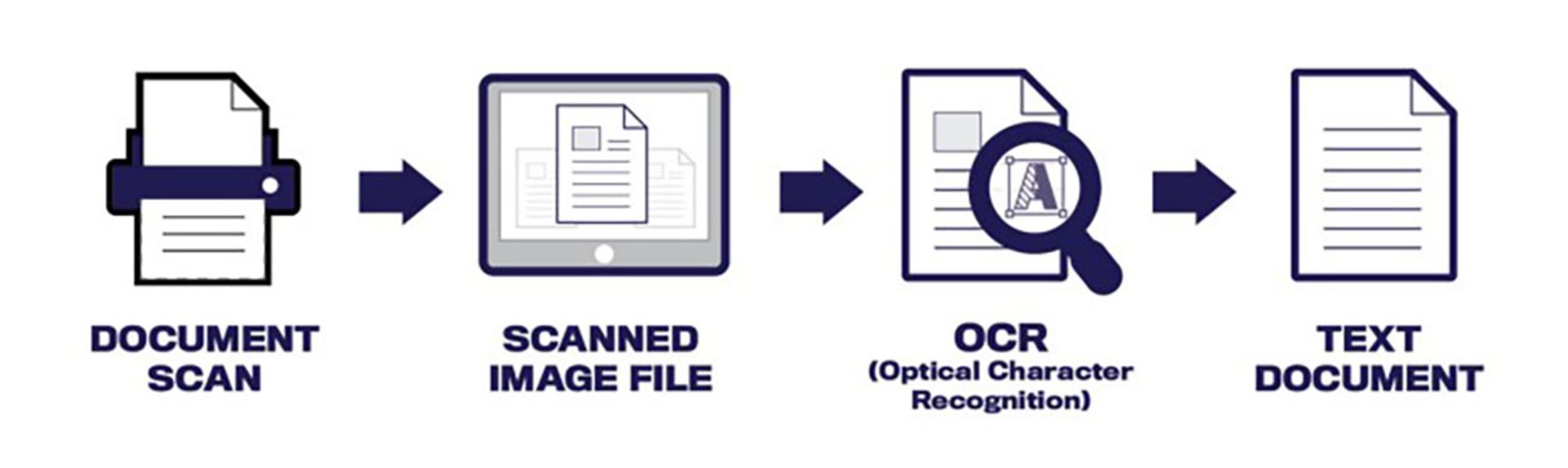
فرایند استفاده از OCR در اسکن متن
قطعا کاربران عادی نیازی به اسکن و تبدیل کردن تعداد زیادی سند و متن در روز ندارند. ما در بهترین حالت بهدنبال تبدیل متن از کتاب یا مقالهای چاپ شده به متن دیجیتالی هستیم. درکنار ابزارهای متعددی که برای اسکن زبان انگلیسی وجود دارد، برای زبان فارسی هم نرمافزارهای متعدد OCR ارائه شدهاند. در ادامه، مراحل آمادهسازی و تبدیل OCR را برای اسناد، شرح میدهیم.
آمادهسازی متن چاپی: ابتدا باید باکیفیتترین نسخهی چاپی از متن مدنظر خود را تهیه کنید. برخی اوقات سند شما قدیمی است و متن باکیفیتی روی آن دیده نمیشود. با برخی راهکارها همچون فتوکپی یا چند بار اسکن و پرینت کردن با تغییر کنتراست، میتوان دقت متن را افزایش داد. کیفیت متن چاپی اولیه در خروجی نهایی OCR تأثیر زیادی دارد. ایرادهایی همچون لکه، کثیف بودن کاغذ، نشت جوهر و غیره، همگی روی تشخیص نهایی نرمافزار تأثیر میگذارند.
اسکن کردن: پس از آمادهسازی متن چاپی مناسب، باید با استفاده از دستگاه اسکنر آن را به فایل دیجیتال تبدیل کنید. اسکنرهای ورقهای نسبت به اسکنرهای تخت برای OCR بهتر هستند، چون کاغذها را با سرعت بهتری دریافت و اسکن میکنند. اکثر برنامههای OCR مدرن، در همان مراحل اسکن کردن، متن دیجیتالی را هم تولید میکنند و سپس اسکن صفحهی بعد را انجام میدهند. بهجای اسکنر میتوان از دوربین دیجیتال با کیفیت بالا نیز استفاده کرد تا تصویری با جزئیات مناسب به کامپیوتر ارائه شود. در برخی موارد میتوان با استفاده از حالت ماکرو، تصویری دقیقتر و شفافتر را از کاراکترها ثبت کرد.
سیاه و سفید کردن: ابزارهای OCR در مرحلهی ابتدایی سند را به نسخهای سیاه و سفید تبدیل میکنند. درواقع تمامی رنگهای اضافهی سند از بین میرود تا تنها دو رنگ باقی بمانند. OCR یک فرایند باینری محسوب میشود. وقتی تصویر بهخوبی به حالت سیاه و سفید با تفاوت زیاد متن و پسزمینه تبدیل شود، بهراحتی هر رنگ سیاه برای پیدا کردن کاراکتر اسکن میشود و هر رنگ سفید، بهمعنای پسزمینه خواهد بود. درنتیجه تبدیل کردن تصویر رنگی به سیاه و سفید، شناسایی کاراکتر را در OCR آسان میکند.
انجام فرایند OCR: برنامههای OCR تفاوتهایی جزئی با هم دارند. البته در اغلب آنها فرایندی ثابت برای اسکن کردن و دریافت خروجی پیاده میشود. برنامه، متن را کاراکتر به کاراکتر و سپس کلمه به کلمه و درنهایت جمله به جمله اسکن میکند. در دهههای گذشته، برنامههای OCR سرعت بسیار پایینی داشتند، اما امروزه فرایند OCR با سرعت بسیار بالایی انجام میشود.
غلطیابی کلی: برخی از برنامهها به کاربر امکان میدهند تا صفحههای اسکن شده را بازبینی و اصلاح کند. برخی از آنها به قابلیتهای غلطیابی املایی مجهز هستند که کلمههایی با احتمال زیادی تشخیص اشتباه را پررنگ کرده و فرایند را برای کاربر ساده میکنند. نمونههای پیشرفتهتر، قابلیت پیدا کردن کلمهی صحیح را هم باتوجهبه کلمههای مجاور پیدا کردهاند. درواقع این برنامهها باتوجهبه کلمههای قبل و بعد، املای صحیح یک کلمهی احتمالا غلط را پیدا میکنند.
تحلیل الگویی: برنامههای OCR پیشرفته، قابلیت شناسایی المانهایی به جز متن را هم دارند و آنها را به المانهای گرافیکی تبدیل میکنند. بهعنوان مثال، برنامه میتواند ستون و جدول و عکس را از متن اسکنشده شناسایی کرده و آنها را در فایل نهایی بهصورت عکس یا جدول نمایش دهد.
غلطیابی انسانی: در پایان پس از استفاده از پیشرفتهترین ابزارهای OCR نیز به غلطیابی نیاز پیدا میکنید. بههرحال این ابزارها هیچگاه کاملا دقیق نیستند و باید مرحلهای برای غلطیابی انسانی هم در اسکنها در نظر بگیرید.

تاریخچه OCR
بسیاری تصور میکنند که OCR در سالهای اخیر توسعه یافته است. درحالیکه این فناوری عمری طولانی در دنیای کامپیوتر دارد. اولین پتنت مرتبط با توانایی خواندن متنهای انسانی توسط ماشینها در سال ۱۹۲۸ بهنام گوستاو تاوسچک قبت شد. پتنت مشابهی هم در سال ۱۹۳۱ بهنام پائول هندل از جنرال الکتریک در ایالات متحده به ثبت رسید. هردو پتنت از ایدهی فتوسلهایی با قابلیت تشخیص الگو از کاغذ بهره میبردند. در سال ۱۹۴۹، دستگاهی در RCA Laboratories ساخته شد که با استفاده از همان فناوری فتوسل، امکان خواندن متن برای نابینایان را با سرعت ۶۰ کلمه در دقیقه فراهم میکرد.
در سال ۱۹۵۰، مهندسی بهنام دیوید اچ شپرد، دستگاهی با قابلیت تبدیل کردن متن کاغذی به فرمتی قابل خواندن در ماشینها ساخت که به ارتش ایالات متحده فروخته شد. او بعدا شرکتی مخصوص OCR بهنام Intelligent Machines Research راهاندازی کرد.شپرد همچنین فونت Farrington B را هم مخصوص خواندن در دستگاههای OCR توسعه داد که امروزه بهنام OCR-7B برای چاپ کردن اعداد روی کارتهای اعتباری استفاده میشود.
لارنس رابرتس یکی دیگر از افراد تأثیرگذار در فناوری OCR بود. او که در MIT تحقیق میکرد، یکی از اولین سیستمهای پیشرفتهی تشخیص متن را با تکیه بر فونت OCR-A توسعه داد. او بعدها در توسعهی اینترنت هم نقش داشت. در همان سالها، رسانهی Reader's Digest و RCA تلاش میکردند تا اولین نمونههای تجاری دستگاه OCR را به بازار عرضه کنند. در دههی ۱۹۶۰، دستگاههای OCR به تجهیزاتی مرسوم در مراکز پستی تبدیل شدند که برای دستهبندی نامهها و مرسولهها و اسکن آدرسها استفاده میشدند. آمریکا و بریتانیا و کانادا از پیشگامان استفاده از فناوری OCR در شرکتهای پستی بودند.
ریموند کورزویل در سال ۱۹۷۴ برنامهای برای اسکن متن و خواندن آن برای افراد نابینا توسعه داد که بعدا شرکت زیراکس آن را خرید. اولین دستگاه همراهبا قابلیت تشخیص دستخط، در سال ۱۹۹۳ تولید شد. Apple Newton MessagePad قابلیت تشخیص دستخط کاربران را روی نمایشگر لمسی داشت. در دههی ۱۹۹۰، توانایی تشخیص دستخط به قابلیتی محبوب و مرسوم، خصوصا در کامپیوترهای همراه PDA تبدیل شد که شرکت پالکم، از پیشگامان تولید آنها بود.
در سال ۲۰۰۰، دانشمندان دانشگاه کارنگی ملون پیشنهاد دادند که از سیستمهای ضد اسکن CAPTCHA برای بهبود برنامههای OCR استفاده شود که هنوز هم نمونههای آنها را میبینیم. در سال ۲۰۰۷ هم رخداد مهم دیگر در تاریخ OCR اتفاق افتاد و با ورود آیفون به بازار گوشیهای هوشمند، توانایی اسکن با دوربین گوشی و تبدیل کردن آن به متن، بیش از همیشه مرسوم شد.

نظرات