
همانطور که در بخشهای اول و دوم صحبت کردیم، در گذشته هم برای ترکیب دو معماری متفاوت در قالب یک تراشه، تلاشهایی صورت گرفته و حتی محصولاتی هم روانهی بازار شدند؛ اما به دو دلیل عمده همگی شکست خوردند.
اول اینکه استفاده از سطح تراشه به شکل بهینه نبود. همیشه بخشهایی بدون استفاده میماند و سیستمعاملی که توان استفاده از همهی بخشها را داشته باشد معرفی نشده بود.
دلیل دوم عملکرد ضعیف در مورد تراشههایی است که از راهکار تبدیل دستورات به شکل نرمافزاری و سختافزاری استفاده میکردند.
ایامدیِ امروز، از نظر تکنولوژی تولید تراشه وضعیت خوبی دارد. هر چند اینتل هنوز هم پرچمدار تکنولوژی پیشرفتهی تولید تراشه است. ترانزیستورها بسیار کوچک شدهاند و اگر مشکل بخشهایی مثل مدارات تراشه به خوبی حل شود، زمینه برای شکوفایی هر چه بیشتر فراهم خواهد شد. میتوان هستههای بزرگ و کوچک با ساختار متفاوت را در کنار هم روی یک تراشه طراحی کرد.
اما مشکل اصلی باز هم وجود دارد و آن استفادهی بهینه از تمام سطح تراشه و به عبارت سادهتر، تمام هستههاست
وضعیت تراشههای ایامدی امروزی
در حال حاضر تراشهای مثل A10-7850K ایامدی را در نظر بگیرید. تراشهای از خانوادهی نوپای کاوری و شامل پردازندهی گرافیکی و اصلی. این تراشه در بازار ایران هم پیدا میشود و از اعضای جدیدترین نسل APU های ایامدی است که البته استقبال زیادی از آن نشده است.

A10-7850K با مساحت 245 میلیمتر مربعی خود، 2.41 میلیارد ترانزیستور را با لیتوگرافی 28 نانومتری HPM دربرگرفته است و یک تراشهی پیچیده به حساب میآید.
اما عملکرد آن چه طور؟ آیا بخش GPU که نیمی از سطح تراشه را اشغال کرده، به هستههای پردازندهی اصلی فرصت قدرتنمایی در برابر هستههای پردازندههای اینتل را میدهد؟ به خصوص هسول و آیویبریج که بسیار سریع و بهینه ظاهر شدهاند؟
به بنچمارکی با نرمافزار فشردهسازی فایلها یعنی Winrar 5.01 توجه کنید.
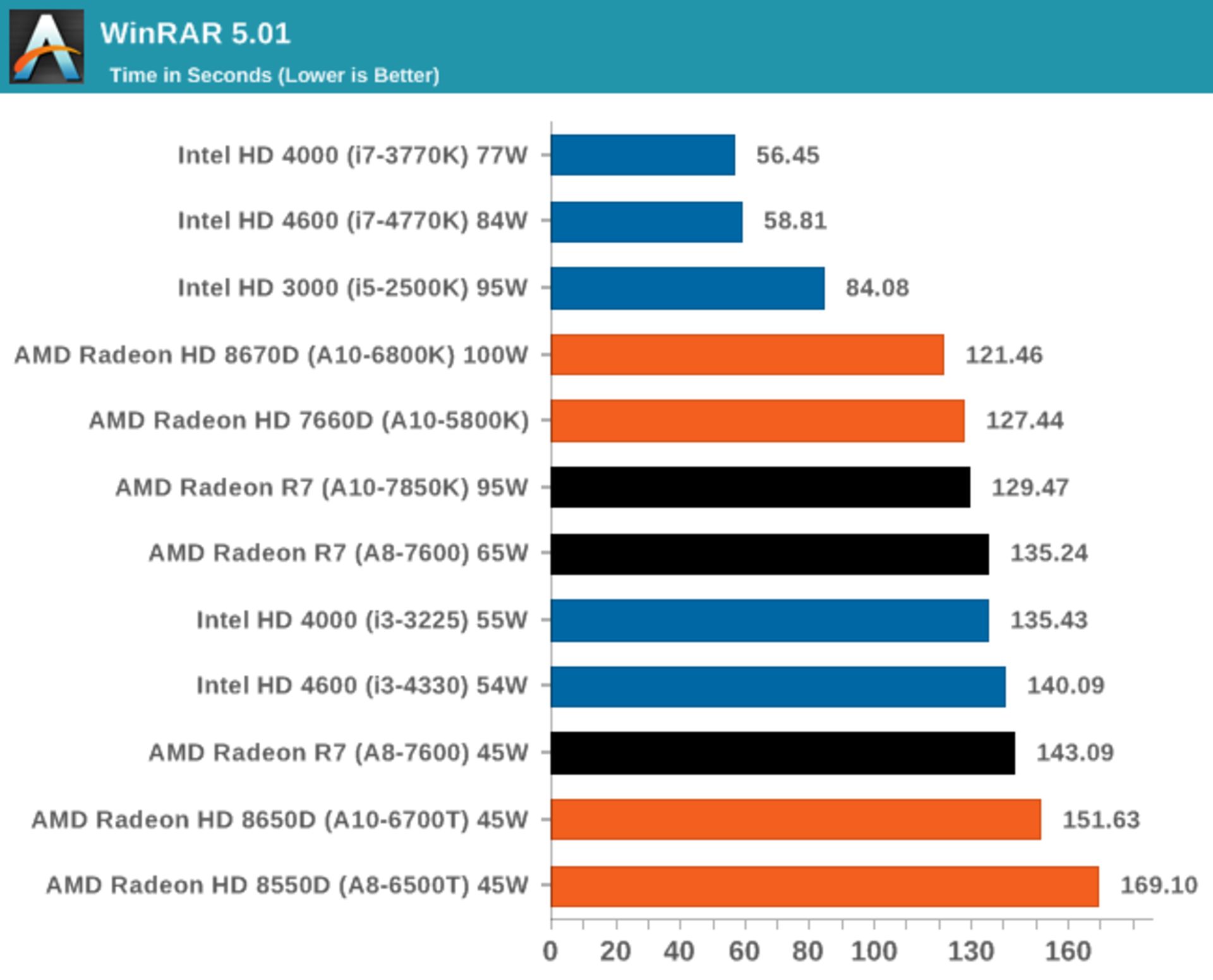
هنوز هم معماری دو نسل قبل یعنی سندی بریج با مدلی مثل Core i5 2500K در پردازش، سریعتر از APUهای ایامدی است.
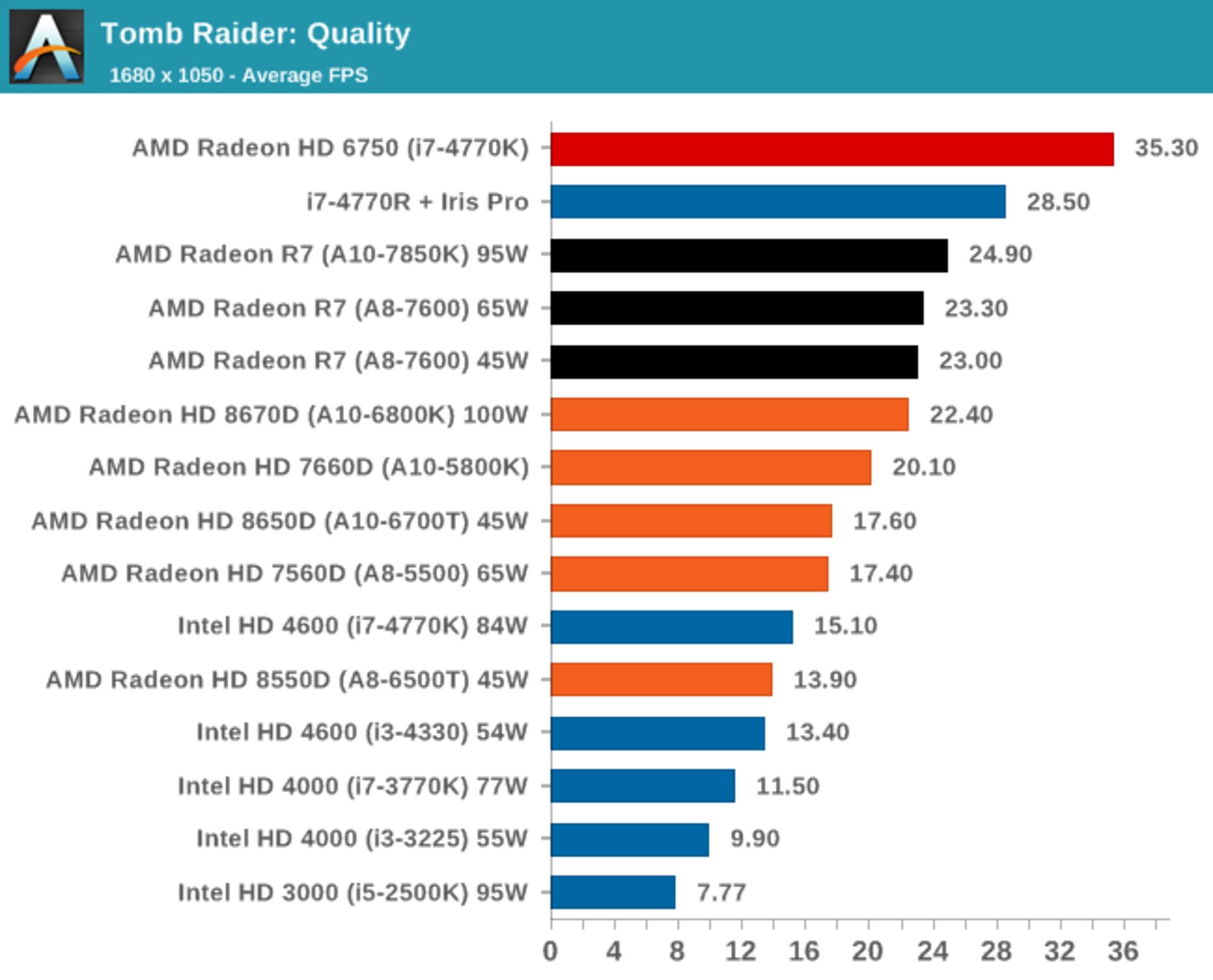
البته کاوری در بخش گرافیکی، برتری بیش از 50 درصدی دارد که برای بازیخورها جالب توجه است. مثلاً در بازی Tomb Raider:
HSA راهی برای پردازش بهینه توسط انواع پردازنده
ترکیب هستههای پردازندهی اصلی و گرافیکی روی یک چیپ، چیزی است که چندین سال توسط اینتل و ایامدی صورت گرفته است. اینتل از نظر هستههای پردازندهی اصلی و ایامدی از نظر پردازندهی گرافیکی پیشتاز بودهاند. در مورد کاوری هم اگر با هسول قیاس کنیم، وضعیت به همین صورت است.
اما تغییر مهمی که در کاوری دیده میشود و در بررسی عمیقی که چندی پیش داشتیم به آن اشاره کردیم، پیادهسازی HSA است. HSA معماری ناهمگن سیستم است و از منابعی مثل پردازندهی اصلی و گرافیکی یا حافظهی کش به صورت مشترک استفاده میکند تا سرعت پردازش افزایش یابد. hUMA یا دسترسی به حافظه به صورت یکنواخت و ناهمگن به هر دو پردازندهی اصلی و گرافیکی اجازه میدهد که مشترکاً و به صورت همزمان از حافظه استفاده کنند:
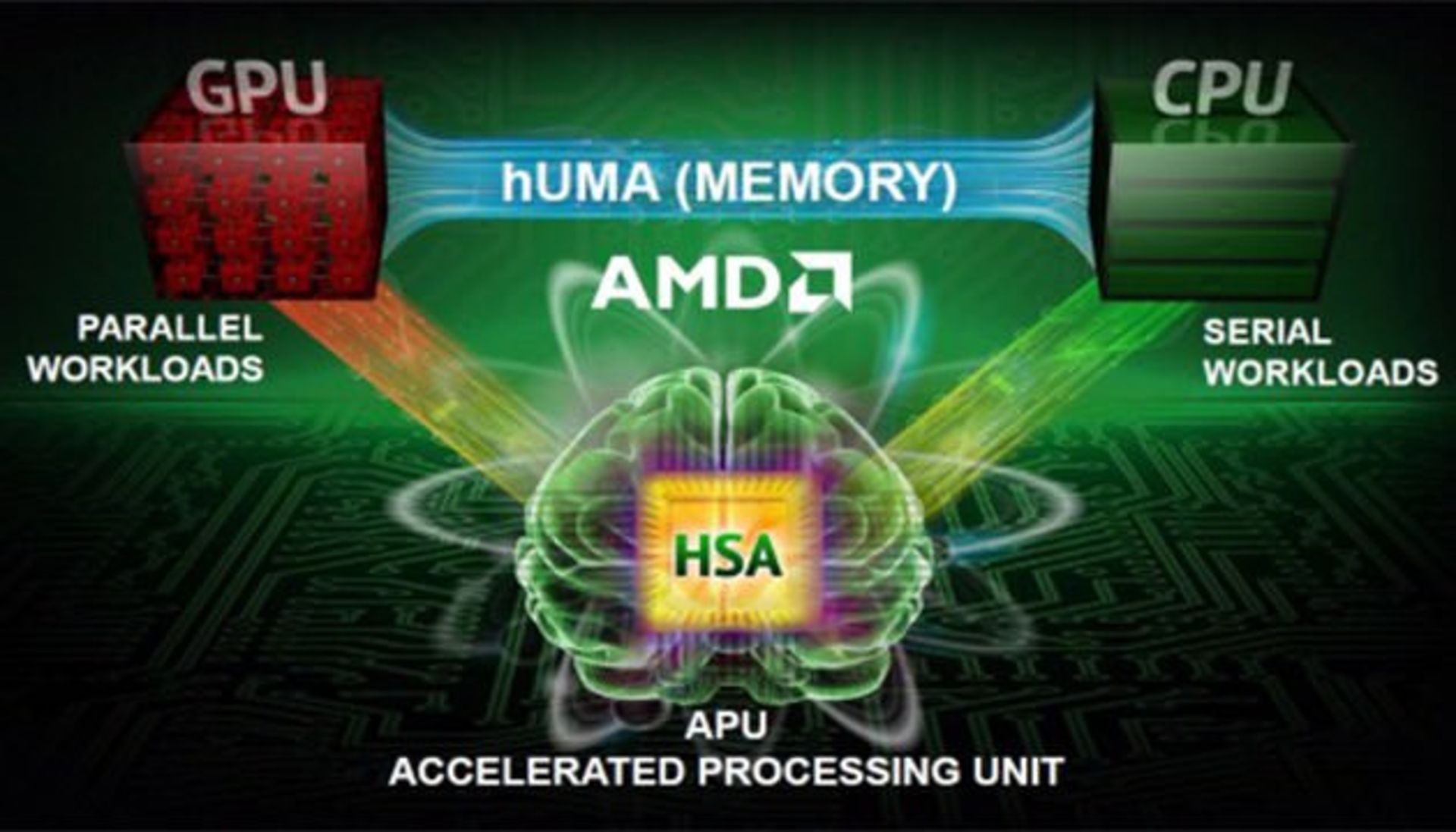
HSA رابطهی نزدیکی بین پردازندهی اصلی، گرافیکی و حافظه برقرار میکند و امور پردازشی به هستههای پردازشی واگذار میشوند
تفاوت HSA با OpenCL یا زبان برنامهنویسی محاسباتی متنباز این است که تنها به اجرای پردازشهای عادی توسط کارت گرافیک مجزا یا پردازندهی گرافیکی مجتمع نمیپردازد؛ بلکه استفاده از حافظهی کش و توسعهی نرمافزاری را هم بهینه میکند. به عنوان مثال در توسعهی نرمافزاری، با گروهی از هستههای محاسباتی سروکار داریم؛ برخی پردازندهی اصلی هستند و برخی پردازندهی گرافیکی. امور پردازشی به هستههای محاسباتی سپرده میشود که ساختارشان متفاوت است. البته امایدی فعلاً روی واسط برنامهنویسی مشغول به کار است تا توسعهی نرمافزارها را برای سازندگان سادهتر کند.

برتری HSA منطقی است؛ ولیکن به پشتیبانی نرمافزاری قوی نیاز دارد. تأثیر زیاد آن در برخی از آزمونهای اولیه کاملاً مشهود است. به گراف زیر توجه کنید:
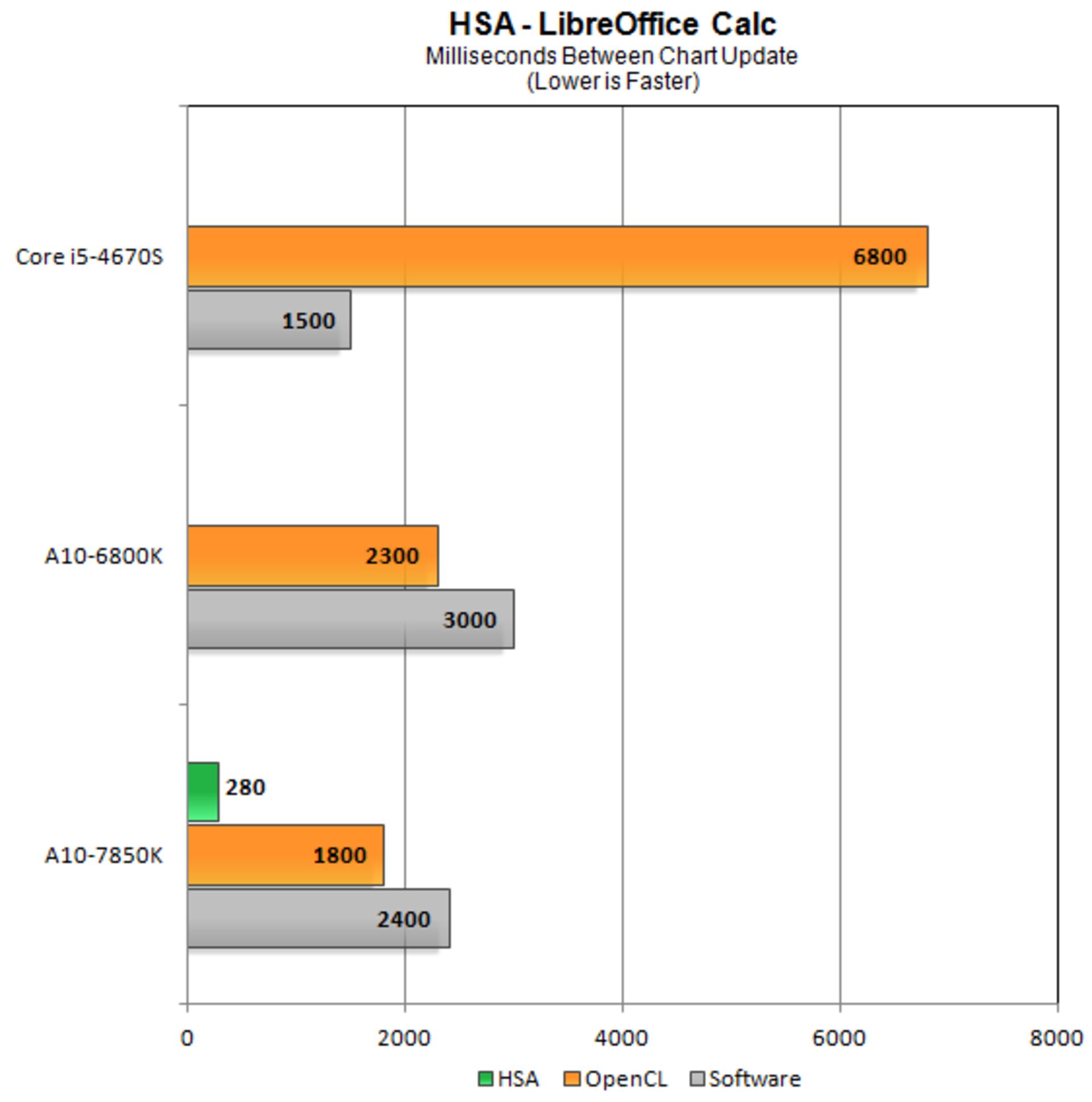
A10-7850K برای انجام محاسبات اکسل در مجموعهی LibreOffice از HSA استفاده کرده و سرعت محاسبات نسبت به OpenCL بیش از 6 برابر شده است.
احتمال اول: HSA کلید استفادهی بهینه از تراشهی ترکیبی
ترکیب جدیدی که ایامدی به آن فکر میکند ممکن است شبیه big.LITTLE باشد که اثر آن را در تراشههای 8 هستهای سامسونگ دیدهایم. Big.LITTLE معماری خاصی است که هستههای بزرگ و کوچک، کممصرف و پرمصرف و به عبارت دیگر قدرتمند و ضعیف را در کنار هم قرار میدهد و بسته به ماهیت بار پردازشی، هستهای که بهینه است، انتخاب میشود. ترکیب Cortex-A15 و A7 در تراشههای اکتای سامسونگ، نمونهای از این ساختار است.
از زمانی که آرم big.LITTLE را معرفی کرده تاکنون، تراشههای مختلفی با این ساختار تولید شده که در ابتدا مشکلاتی داشتند. مثلاً بار پردازشی به درستی بین هستهها تقسیم نمیشد یا برخی دیگر قادر به استفادهی همزمان از تمام هستهها نبودند. این مشکلات بیشتر گریبانگیر سامسونگ شده؛ ولیکن امروز دیگر مشکل خاصی وجود ندارد. حتی کوآلکام هم برای پردازندههای 64 بیتی خود در سال 2015، به استفاده از big.LITTLE روی آورده است.
کار ایامدی شبیه به ترکیب پلتفرم آرم و x86 به صورت big.LITTLE است. IBM در سوییچکردن بین هستهها تأخیر نسبتاً زیادی داشت؛ لذا ایامدی باید در خصوص پشتیبانی عمیق سیستمعامل که در تخصص مایکروسافت یا گوگل است، تلاش زیادی کند. سیستمعامل باید دقیقاً و سریعاً بار پردازشی را شناسایی کرده و به هستههای آرم یا x86 واگذار کند. با استفاده از HSA حافظهی کش به صورت مشترک بین هستههای x86 و آرم و نیز پردازندهی گرافیکی مورد استفاده قرار میگیرد و لذا تأخیر زیادی که موجب کاهش عملکرد باشد و شکست IBM را تکرار کند، از بین میرود.
HSA ارتباط بهینهای بین هستههای آرم و x86 و همچنین پردازندهی گرافیکی و حافظهی کش برقرار میکند
یک راه حل دوم هم استفاده از ماشینهای مجازی یا Virtual Machine برای اجرای نرمافزارهای آرم روی x86 و بالعکس است. یک نرمافزار ماشین مجازی مثل Virtual Box، اجرای یک سیستمعامل به صورت مجازی در سیستمعامل اصلی را ممکن میکند. مثلاً اجرای ویندوز XP در ویندوز 8. شبیهسازی جدید میتواند به صورت کاملاً نرمافزاری نباشد و از سختافزار متناسب استفاده کند. به عنوان مثال در محیط Windows 8 میتوان ماشین مجازی خاصی داشت که نرمافزارهای آرم را روی هستههای مربوطه اجرا میکند. لذا کارایی آن به مراتب بالاتر از شبیهسازی صرفاً نرمافزاری است.
احتمال دوم: هستههای آرم در خدمت پردازندهی گرافیکی
شاید با اطلاعات اندکی که در مورد پروژهی دنور انویدیا منتشر شده، صحبتکردن از هستههای آرم در کنار پردازندهی گرافیکی برای بهینهسازی اجرای دستورات OpenCL توسط پردازندهی گرافیکی، کمی زود به نظر برسد؛ اما به هر حال این تصمیمی است که انویدیا چند سال پیش گرفته و مشغول کار روی آن است.
ابتدا به اسلایدی از سال 2012 توجه کنید:
GPGPU به معنی استفادهی عمومی از پردازندهی گرافیکی است، به عبارت دیگر پردازندهی گرافیکی در امور غیر گرافیکی هم به CPU کمک میکند
پروژهی دنور قرار است رابطهی عمیقی بین پردازندهی اصلی و گرافیکی برقرار کند. به همین علت از هستههای آرم در کنار پردازندهی گرافیکی استفاده میشود. در اسلاید فوق تعداد زیادی واحد چندپردازشی استریم یا SM در کنار 8 هستهی پردازندهی اصلی قرار گرفته است. هستههای CPU در این ساختار به مدیریت تردهای پردازشی میپردازند تا امور کلی پردازشی توسط پردازندهی گرافیکی به شکل بهینهتری اجرا شود. اینکه هستههای آرم در این مدیریت بار پردازشی چه قدر مؤثر واقع میشوند، مشخص نیست؛ اما قطعاً مؤثر هستند.
هستههای ARM بار پردازش عمومی را برای هستههای پردازندهی گرافیکی، مدیریت میکنند
پردازندهی اصلی تردهای کمتعداد را با سرعتی فوقالعاده بالا اجرا میکند و پردازندهی گرافیکی در اجرای تردهای موازی استاد است. لذا اگر قرار باشد امور کلی توسط پردازندهی گرافیکی انجام شود، استفاده از هستههای آرم که بار پردازشی را مدیریت کنند، مفید فایده خواهد بود.
اما اگر ایامدی به دنبال پیادهسازی همین روش در یک APU باشد، مشکلی در مورد پهنای باند نخواهد داشت یا لااقل مشکلات کمتری دارد. امروزه در GPGPU یک مشکل جدی وجود دارد که به انتقال اطلاعات بین پردازندهی اصلی و گرافیکی مربوط میشود. همانطور که در اسلاید فوق مشاهده میکنید، در معرفی دنور به تعداد زیادی حافظهی DRAM اشاره شده است. حتی ممکن است NVLink که برای افزایش پهنای باند به عنوان جایگزین احتمالی PCI-Express معرفی شده هم بخشی از راه حل انویدیا برای مشکل پهنای باند باشد. در اجرای یک بازی، پهنای باند ارتباط پردازندهی اصلی و کارت گرافیک، محدودیت زیادی ایجاد نمیکند؛ اما در GPGPU به پهنای باند بسیار بالایی نیاز است. درست مثل پهنای باند کش در پردازنده.

ایامدی میتواند از HSA به بهترین شکل استفاده کرده و حافظهی کش روی APU را جهت تأمین پهنای باند بسیار بالا مورد استفاده قرار دهد. به این ترتیب OpenCL و اجرای امور کلی پردازشی توسط بخش گرافیکی تراشه، بهینهتر از تراشههای رقیب انجام میشود.
در واقع HSA با افزایش پهنای باند، در استراتژی ایامدی نقش کلیدی بازی میکند.
جمعبندی و سخن آخر
پروژهی Sky Bridge و موضوع ترکیب هستههای مبتنی بر ARM و x86 در یک تراشه، دلایل مختلفی ممکن است داشته باشد؛ احتمال اول این است که ایامدی به دنبال معرفی تراشهای کاملاً متفاوت است که امور پردازشی سبک و سنگین را به ترتیب توسط هستههای کممصرف آرم و هستههای سریع x86 انجام میدهد؛ آن هم توسط یک تراشهی متفاوت.
احتمال دوم سرمایهگذاری روی GPGPU است؛ شاید ایامدی میخواهد از هستههای آرم برای توزیع بهتر پردازشهای عمومی محول شده به بخش پردازندهی گرافیکی استفاده کند.
هر دو احتمال با در نظر گرفتن ویژگیهای HSA مفید است. در HSA همهچیز توسط یک تراشه و با همکاری پردازندههای مختلف انجام میشود. رابطهی کش و پردازندهها بهینه شده است و پردازندهها میتوانند در صورت نیاز در آن واحد از حافظه استفاده کنند؛ چیزی که نام hUMA برای آن انتخاب شده است. لذا اسکایبریج شاید مثل معنای خود، پلی به سوی آسمان شکوفایی پردازش باشد و دنیای پردازش را کمی متحول کند.
البته این روند، موضوع جدیدی نیست. زبان برنامهنویسی محاسباتی متن باز یا OpenCL، واسط برنامهنویسی Mantle که ایامدی برای تعامل بهتر پردازندهها و حافظه معرفی کرده و حتی DirectX 12 مایکروسافت، همگی تلاشهایی برای استفادهی بهتر از تمام قدرت پردازشی سختافزار هستند. اما قطعاً AMD در این عرصه سالها تلاش کرده و طبق اظهارات Rory Read، مدیرعامل این کمپانی، میخواهد تراشههای خاص با ویژگیهای متفاوت طراحی کند.
شما چه نظری در مورد آیندهی HSA و تراشههای ترکیبی AMD دارید؟ آیا پروژهی دنور انویدیا و پیشرفتهای اینتل راه را برای پیشرفت ایامدی تنگ میکنند و مشکلات، مانع از به ثمر رسیدن درخت HSA میشود یا بالأخره ایامدی با معرفی تراشههای اختصاصی خود که از نظر نرمافزاری به خوبی پشتیبانی میشوند، به اوج میرسد؟


نظرات